- results
- .gitignore
- 1Numpy 基础.ipynb
- 2Matplotlib 基础.ipynb
- 3Pandas 基础.ipynb
- 4Sklearn 基础.ipynb
- 5决策树.ipynb
- 6神经网络学习.ipynb
- _overview.md
- _readme.ipynb
- coding_here.ipynb
- essay1_ch.txt
- essay1_en.txt
- essay2_ch.txt
- essay2_en.txt
- essay3_ch.txt
- essay3_en.txt
- iris.csv
- mnist.npz
- mnist.py
- model.h5
- myModel.pkl
- out.txt
- pie.png
- Pokemon.csv
- search.py
- 练习题-matplotlib.ipynb
- 练习题-Numpy.ipynb
- 练习题-Pandas.ipynb
- 练习题-scikit-learn.ipynb
{kind=link}
6神经网络学习.ipynb @96fc089 — view markup · raw · history · blame
神经网络学习¶
人工智能是什么呢?¶
人工智能被分为强人工智能和弱人工智能:
- 强人工智能:在各方面都能够和人类比肩的人工智能,“一种宽泛的心理能力,能够进行思考、计划、解决问题、抽象思理解复杂理念、快速学习和从经验中学习等”
- 弱人工智能:擅长于单个方面的人工智能,比如AlphaGo。
弱人工智能,本质上还是人类为计算机设计的算法,一系列定义良好的计算过程,能够将输入数据转化成输出数据。
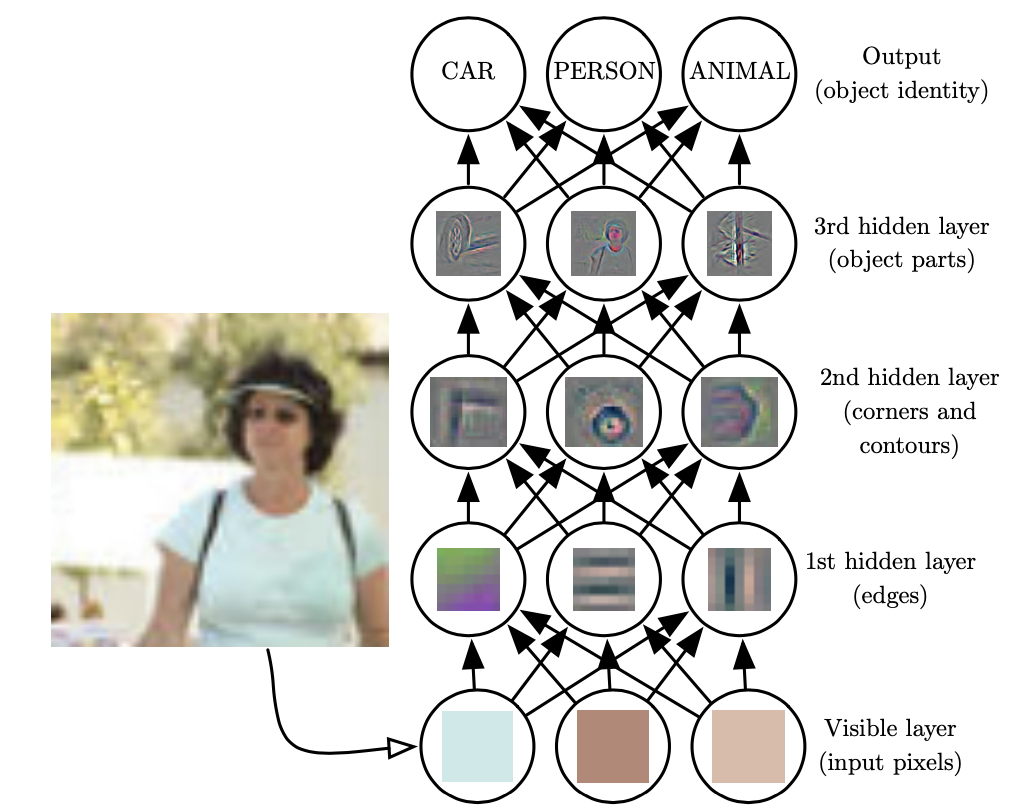
神经网络模拟人脑神经元的连接来达到学习功能,通过逐层抽象将输入数据逐层映射为概念等高等语义。

1 人脑神经机制¶
首先,人脑神经元的活动和学习机制是怎样的呢?
from IPython.display import IFrame
src = 'https://files.momodel.cn/nn_brain_3.pptx'
IFrame('https://view.officeapps.live.com/op/view.aspx?src='+src, width=800, height=600)
神经学假说认为:
 |
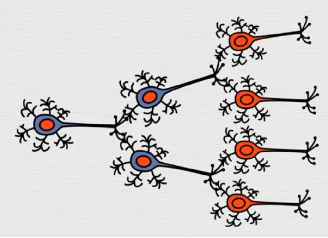 |
 |
高层的特征是低层特征的组合,从低层到高层的特征表示越来越抽象,越来越能表现语义。
人工智能中神经网络正是体现“逐层抽象、渐进学习”机制的学习模型。
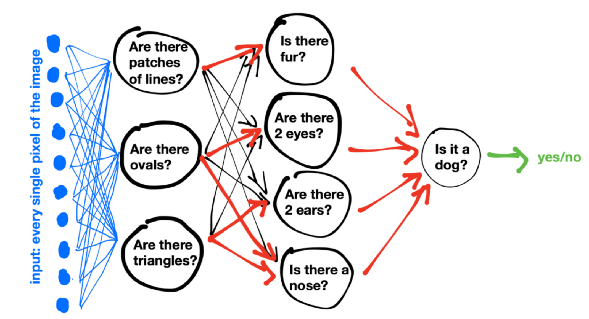
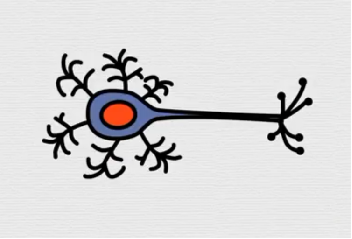
人眼在辨识图片时,会先提取边缘特征,再识别部件,最后再得到最高层的模式。
神经元的功能:
- 物理反应:将前序神经元所传递过来的信息按联结权重累加
$ 神经元i获得信息 = 神经元k信息 \times 联结权重k + 神经元l信息 \times 联结权重l + 神经元m信息 \times 联结权重m $
- 化学反应:对神经元i获得的信息施以一个非线性变换(通过激活函数),激活若干信息、而非“来者不拒”
- 信息流通:将神经元非线性变换后所得的信息继续向后传递
2 感知机模型¶
2.1 感知机模型:¶
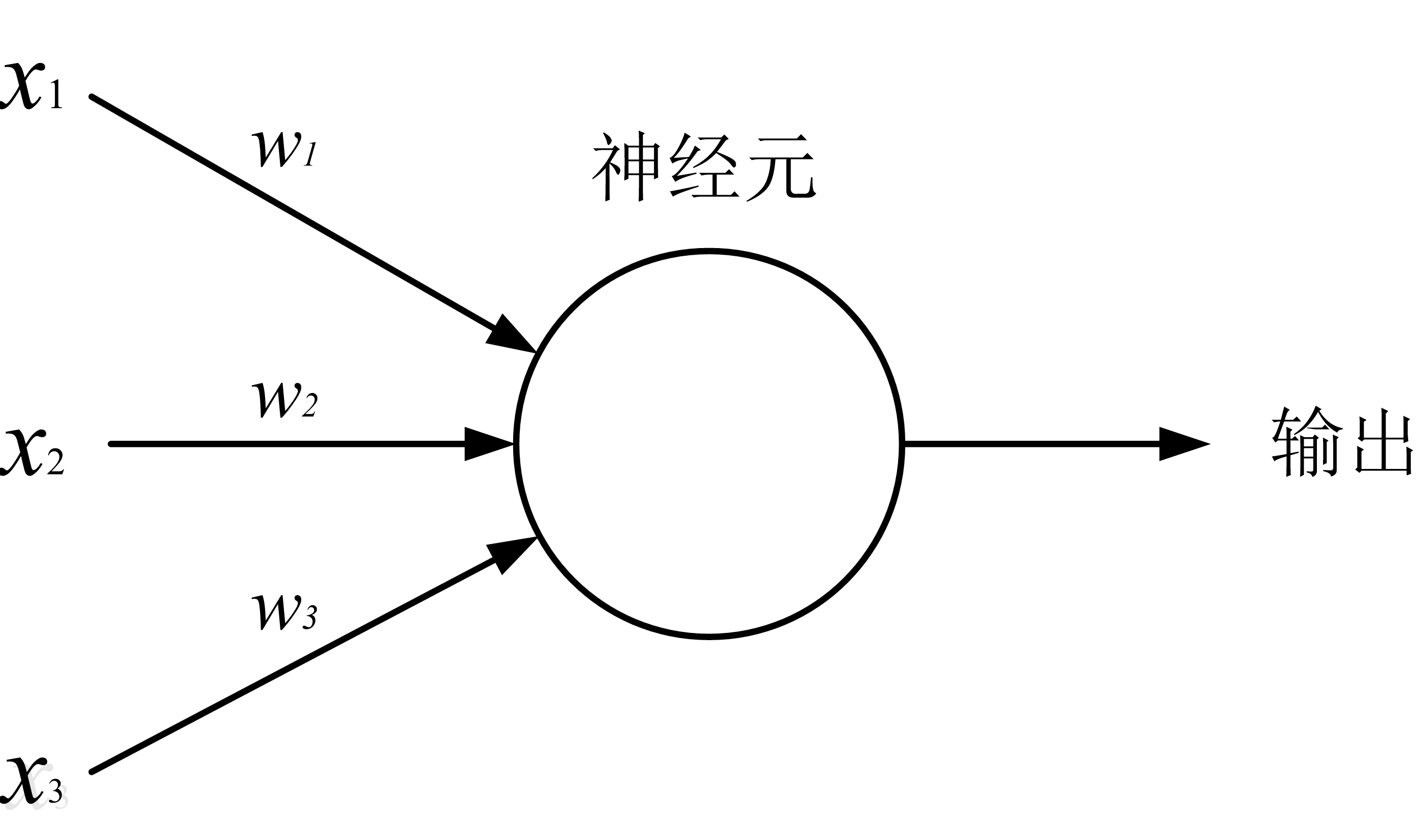 |
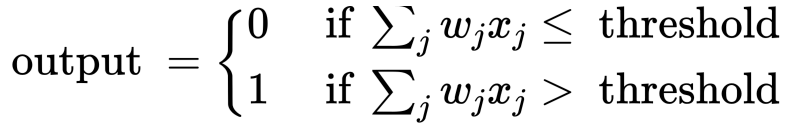 |
输入项:3个,$x_1,x_2,x_3$
神经元:1个,用圆圈表示
权重:每个输入项均通过权重与神经元相连(比如 $w_i$ 是 $x_i$ 与神经元相连的权重)
输出:1个
工作方法:
- 计算输入项传递给神经元的信息加权总和,即:$y_{sum} = w_1x_1+w_2x_2+w_3x_3$
- 如果 $y_{sum}$ 大于某个预定阀值(比如 0.5),则输出为 1,否则为 0 。
2.2 激活函数¶
在输出的判断上,其实不仅可以简单的按照阈值来判断,可以通过一个函数来进行计算,这个函数称为激活函数。
常见的激活函数有: sigmoid,tanh,relu 等。
下面我们看看这些激活函数的曲线图。
import numpy as np
import matplotlib.pyplot as plt
import warnings
warnings.filterwarnings("ignore")
def plot_activation_function(activation_function):
"""
绘制激活函数
:param activation_function: 激活函数名
:return:
"""
x = np.arange(-10, 10, 0.1)
y_activation_function = activation_function(x)
# 绘制坐标轴
ax = plt.gca()
ax.spines['right'].set_color('none')
ax.spines['top'].set_color('none')
ax.xaxis.set_ticks_position('bottom')
ax.yaxis.set_ticks_position('left')
ax.spines['bottom'].set_position(('data', 0))
ax.spines['left'].set_position(('data', 0))
# 绘制曲线图
plt.plot(x, y_activation_function)
# 展示函数图像
plt.show()
1.sigmoid函数¶
Sigmoid函数是一个在生物学中常见的S型函数,也称为S型生长曲线。在信息科学中,由于其单增以及反函数单增等性质,Sigmoid函数常被用作神经网络的阈值函数,将变量映射到0,1之间。
def sigmoid(x):
"""
sigmoid函数
:param x: np.array 格式数据
:return: sigmoid 函数
"""
y =
return y
# 绘制 sigmoid 函数图像
plot_activation_function(sigmoid)
def sigmoid(x):
"""
sigmoid函数
:param x: np.array 格式数据
:return: sigmoid 函数
"""
y = 1/(1+np.exp(-x))
return y
# 绘制 sigmoid 函数图像
plot_activation_function(sigmoid)

优点:
- Sigmoid 函数的输出映射在(0,1)之间,单调连续,输出范围有限,优化稳定,可以用作输出层。它在物理意义上最为接近生物神经元。
- 求导容易。
缺点:
- 由于其软饱和性,容易产生梯度消失,导致训练出现问题。
- 其输出并不是以0为中心的。
def tanh(x):
"""
tanh函数
:param x: np.array 格式数据
:return: tanh 函数
"""
y =
return y
# 绘制 tanh 函数图像
plot_activation_function(tanh)
def tanh(x):
"""
tanh函数
:param x: np.array 格式数据
:return: tanh 函数
"""
y = (1-np.exp(-2*x))/(1+np.exp(-2*x))
return y
# 绘制 tanh 函数图像
plot_activation_function(tanh)

优点:
- 比Sigmoid函数收敛速度更快。
- 相比Sigmoid函数,其输出以0为中心。
缺点:
- 还是没有改变Sigmoid函数的最大问题——由于饱和性产生的梯度消失。
3.ReLU函数¶
Relu激活函数(The Rectified Linear Unit),用于隐层神经元输出。公式如下:
def relu(x):
"""
relu 函数
:param x: np.array 格式数据
:return: relu 函数
"""
y =
return y
# 绘制 relu 函数
plot_activation_function(relu)
def relu(x):
"""
relu 函数
:param x: np.array 格式数据
:return: relu 函数
"""
y = np.maximum(0,x)
return y
# 绘制 relu 函数
plot_activation_function(relu)

优点:
- 因为它线性、非饱和的形式,ReLU在SGD中能够快速收敛。
- 有效缓解了梯度消失的问题。
- 提供了神经网络的稀疏表达能力。
缺点:
- 随着训练的进行,可能会出现神经元死亡,权重无法更新的情况。如果发生这种情况,那么流经神经元的梯度从这一点开始将永远是0。也就是说,ReLU神经元在训练中不可逆地死亡了。
单层感知机实例¶
我们根据上面的定义可以编写一个简单的感知机模型。
def perceptron(x, w, threshold):
"""
感知机模型
:param x: 输入数据 np.array 格式
:param w: 权重 np.array 格式,需要与 x 一一对应
:param threshold: 阀值
:return: 0或者1
"""
x = np.array(x)
w = np.array(w)
#计算信息加权总和
y_sum =
# 计算输出大于阀值返回 1,否则返回 0
output =
return output
# 输入数据
x = np.array([1, 1, 4])
# 输入权重
w = np.array([0.5, 0.2, 0.3])
# 返回结果
perceptron(x, w, 0.8)
def perceptron(x, w, threshold):
"""
感知机模型
:param x: 输入数据 np.array 格式
:param w: 权重 np.array 格式,需要与 x 一一对应
:param threshold: 阀值
:return: 0或者1
"""
x = np.array(x)
w = np.array(w)
#计算信息加权总和
y_sum = np.sum(w * x)
# 计算输出大于阀值返回 1,否则返回 0
output = 1 if y_sum > threshold else 0
return output
# 输入数据
x = np.array([1, 1, 4])
# 输入权重
w = np.array([0.5, 0.2, 0.3])
# 返回结果
perceptron(x, w, 0.8)
3 神经网络¶
3.1 神经网络的结构¶
神经网络:相互连接形成一个无环图的神经元集合。
神经网络通常由不同的神经元层组织而成,常见的层类型有:
- 全连接层
- 卷积层
- 池化层
- Dropout层
- RNN层
- ......
首先,我们来看一个完全由全连接层联结起来的神经网络,也被称为多层感知器(Multilayer Perceptrons, MLP)
神经网络架构示意图如下:
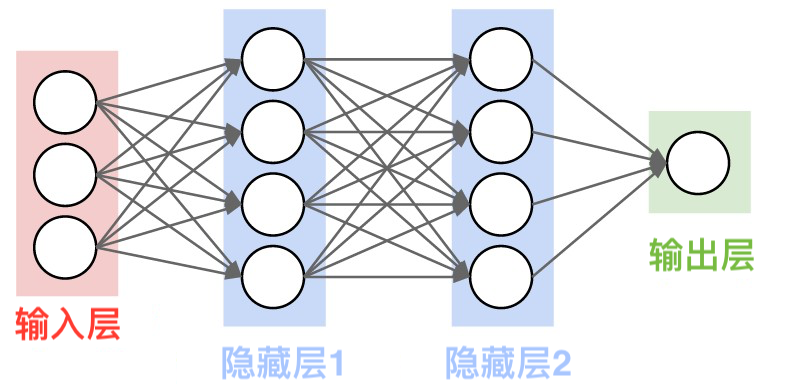
与感知机的不同,神经网络:
- 输入层和输出层之间存在若干隐藏层。
- 每个隐藏层中包含若干神经元。
3.2 补充材料:梯度下降与误差反向传播¶
正向传播 与 反向传播¶
- 前馈神经网络接收一个输入 $x$ ,并产生一个输出 $\hat{y}$ 信息正向流过网络,称为正向传播(forward propagation)
- 训练过程中:正向传播可以一直继续下去直到产生一个标量代价 $J(\theta)$ .
- 反向传播:允许信息从代价出发,反向流过网络
误差反向传播¶
- 核心问题:给定某个函数 ,计算f在点x处的梯度$\epsilon{f(x)}$
- 在神经网络中, 对应于损失函数,而输入x 则是由训练数据和神经网络权重参数构成
- 反向传播:通过递归地应用链式法则来计算表达式梯度的一种方法
反向传播指的仅仅是计算梯度的方法,并不是多层神经网络的整个学习算法!
简单表达式与梯度解释:
梯度:是一个向量,表示函数在该点处沿着该方向变化最快,变化率最大
而对于单变量的情况下,梯度也就等同于它的导数。

复合表达式和链式法则:
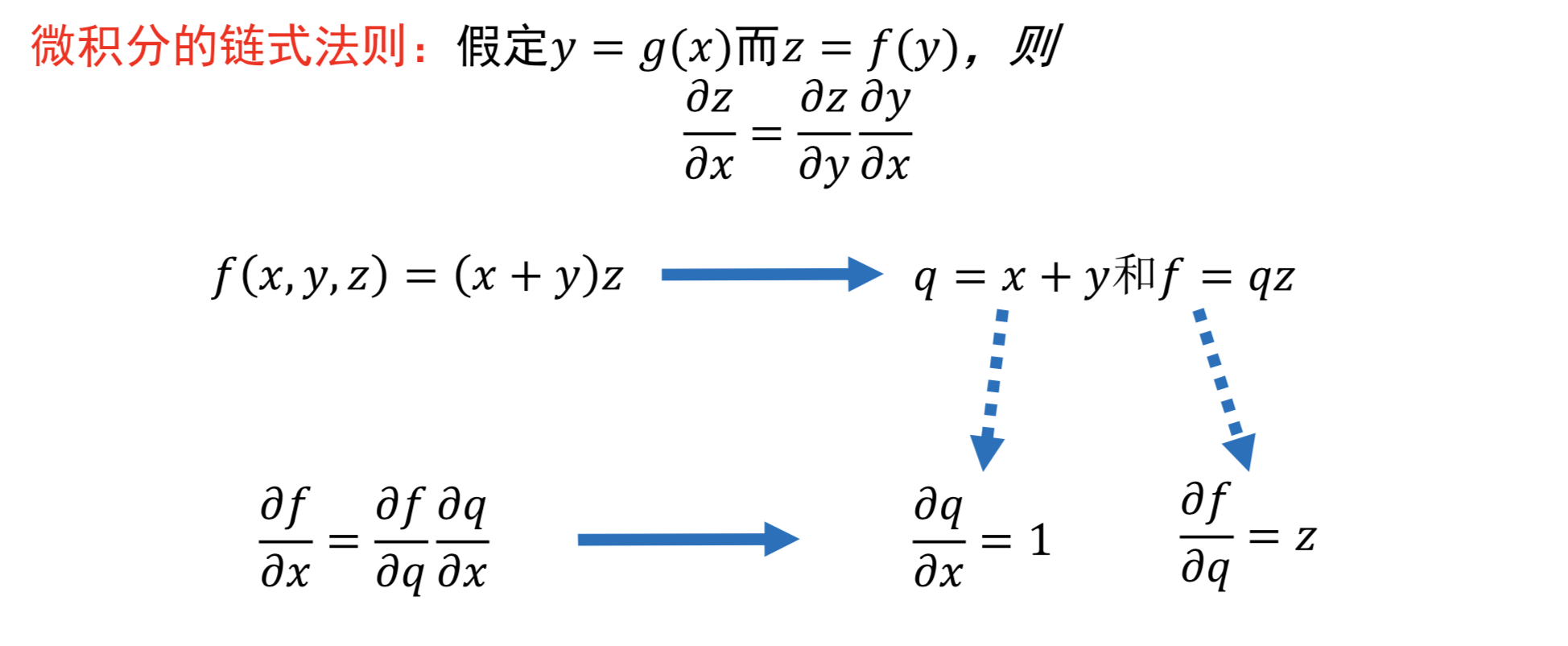
反向直播的直观理解: $f(x,y,z) = (x+y)z, q=x+y, f=qz$
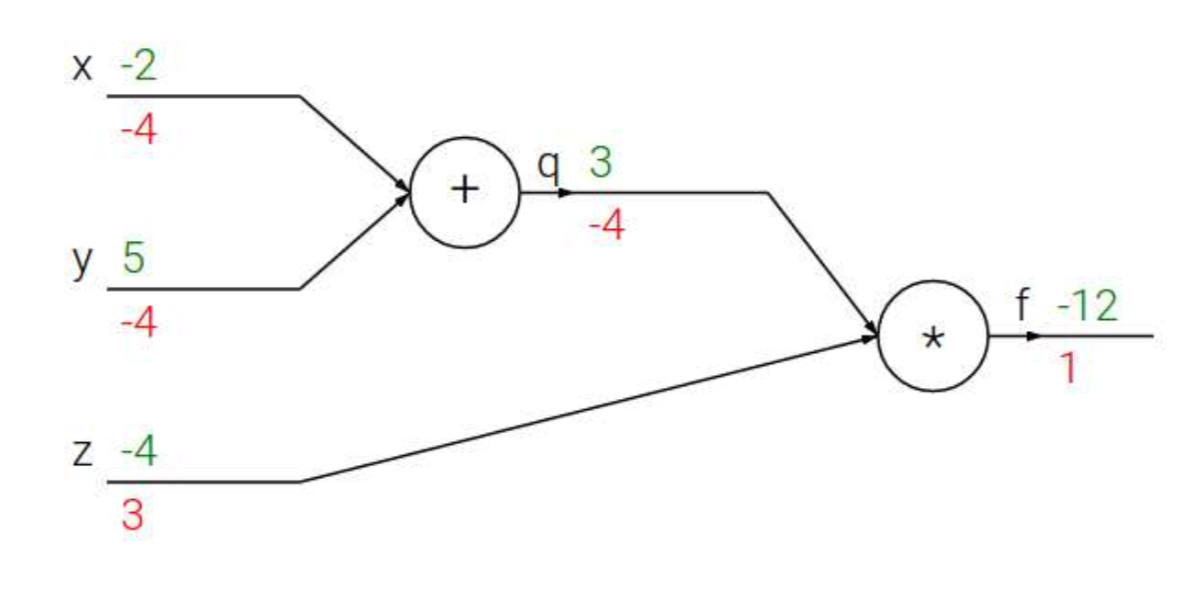
3.3 神经网络实现MNIST手写数字分类¶
好,我们接下来,依旧使用MNIST手写数字数据集来实现一个神经网络的分类方法。
采用 keras 框架搭建一个神经网络解决手写体数字识别问题。
- 导入相关包
# 数据集 mnist
from tensorflow.keras.datasets import mnist
# 序列模型 Sequential
from tensorflow.keras.models import Sequential
# 神经网络层 Dense,Activation,Dropout
from tensorflow.keras.layers import Dense, Activation, Dropout
# 工具 np_utils
from tensorflow.python.keras.utils.np_utils import to_categorical
import warnings
warnings.filterwarnings("ignore")
!mkdir -p ~/.keras/datasets
!cp ./mnist.npz ~/.keras/datasets/mnist.npz
- 下载 MNIST 数据集并将它们转换为模型所能使用的格式。
# 获取数据
(X_train, y_train),(X_test,y_test) = mnist.load_data()
# 将训练集数据形状从(60000,28,28)修改为(60000,784)
X_train = X_train.reshape(len(X_train), -1)
X_test = X_test.reshape(len(X_test), -1)
通过plot查看数据集情况
import matplotlib.pyplot as plt
# 查看一些图片
def plot_images(imgs):
"""绘制几个样本图片
:param show: 是否显示绘图
:return:
"""
sample_num = min(9, len(imgs))
img_figure = plt.figure(1)
img_figure.set_figwidth(5)
img_figure.set_figheight(5)
for index in range(0, sample_num):
ax = plt.subplot(3, 3, index + 1)
ax.imshow(imgs[index].reshape(28, 28), cmap='gray')
ax.grid(False)
plt.margins(0, 0)
plt.show()
plot_images(X_train)

对图像数据进行数据处理。
# 将数据集图像像素点的数据类型从 uint8 修改为 float32
X_train = X_train.astype('float32')
X_test = X_test.astype('float32')
# 把数据集图像的像素值从 0-255 放缩到[-1,1]之间
X_train = (X_train - 127) / 127
X_test = (X_test - 127) / 127
# 数据集类别个数
nb_classes = 10
# 把 y_train 和 y_test 变成了 one-hot 的形式,即之前是 0-9 的一个数值,
# 现在是一个大小为 10 的向量,它属于哪个数字,就在哪个位置为 1,其他位置都是 0。
y_train = to_categorical(y_train, nb_classes)
y_test = to_categorical(y_test, nb_classes)
- 搭建神经网络模型
def create_model():
"""
采用 keras 搭建神经网络模型
:return: 神经网络模型
"""
# 选择模型,选择序贯模型(Sequential())
model = Sequential()
# 添加全连接层,共 512 个神经元
model.add(Dense(512, input_shape=(784,)))
# 添加激活层,激活函数选择 relu
model.add(Activation('relu'))
# 添加全连接层,共 512 个神经元
model.add(Dense(512))
# 添加激活层,激活函数选择 relu
model.add(Activation('relu'))
# 添加全连接层,共 10 个神经元
model.add(Dense(10))
# 添加激活层,激活函数选择 softmax
model.add(Activation('softmax'))
return model
# 实例化模型
model = create_model()
- 训练和测试神经网络模型
def fit_and_predict(model, model_path):
"""
训练模型、模型评估、保存模型
:param model: 搭建好的模型
:param model_path:保存模型路径
:return:
"""
# 编译模型
model.compile(optimizer='Adam',
loss='categorical_crossentropy',
metrics=['accuracy'])
# 模型训练
model.fit(X_train, y_train, epochs=5, batch_size=64)
# 保存模型
model.save(model_path)
# 模型评估,获取测试集的损失值和准确率
loss, accuracy = model.evaluate(X_test, y_test)
# 打印结果
print('Test loss:', loss)
print("Accuracy:", accuracy)
# 训练模型和评估模型
fit_and_predict(model, model_path='./model.h5')
那么,神经网络模型,是如何识别这一张张图片的呢?以下,我们使用通过下面几个小视频,你会更好的理解神经网络:
神经网络的整体模型
通过激活函数,神经元将每一层的“化学状态”传递到下一层。
对于MNIST的图像分类,这里需要传递的信息就是图形信息:
图像信息在神经网络中的传递:
具体表述成函数的形式,一个第二层的神经元的值就应该是这样获得的:
全连接网络中的参数设置。
def create_model1():
"""
搭建神经网络模型 model1,比 model 少一层隐藏层
:return: 模型 model1
"""
# 选择模型,选择序贯模型(Sequential())
model =
# 添加全连接层,共 512 个神经元
model.add()
# 添加激活层,激活函数选择 relu
model.add()
# 添加全连接层,共 10 个神经元
model.add()
# 添加激活层,激活函数选择 softmax
model.add()
return model
# 搭建神经网络
model1 = create_model1()
# 训练神经网络模型,保存模型和评估模型
fit_and_predict(model1, model_path='./model1.h5')
- 修改两层隐藏层神经元的数量,然后训练模型得出准确率。
def create_model2():
"""
搭建神经网络模型 model2,隐藏层的神经元数目比 model 少一半
:return: 神经网络模型 model2
"""
# 选择模型,选择序贯模型(Sequential())
model = Sequential()
# 添加全连接层,共 256 个神经元
model.add()
# 添加激活层,激活函数选择 relu
model.add()
# 添加全连接层,共 256 个神经元
model.add()
# 添加激活层,激活函数选择 relu
model.add()
# 添加全连接层,共 10 个神经元
model.add()
# 添加激活层,激活函数选择 softmax
model.add()
return model
# 搭建神经网络模型
model2 = create_model2()
# 训练神经网络模型,保存模型并评估模型
fit_and_predict(model2,model_path='./model2.h5')
- 输入一个手写数字,比较三种模型输出结果的差异,对其差异进行分析解释。
import numpy as np
np.set_printoptions(suppress=True)
from tensorflow.keras.models import load_model
# 加载模型
model = load_model('./model.h5')
model1 = load_model('./model1.h5')
model2 = load_model('./model2.h5')
# 预测结果
predict_results = np.round(model.predict(X_test)[0],3)
# predict_results1 = np.round(model1.predict(X_test)[0],3)
# predict_results2 = np.round(model2.predict(X_test)[0],3)
# 打印预测结果
print('原始模型\n其各类别预测概率:%s,预测值: %s,真实值:%s\n' % (predict_results,np.argmax(predict_results),np.argmax(y_test[0])))
print('只有一个隐藏层的模型\n其各类别各类别预测概率:%s,预测值: %s,真实值:%s\n' % (predict_results1,np.argmax(predict_results1),np.argmax(y_test[0])))
print('隐藏神经元数量更改后的模型\n其各类别预测概率:%s,预测值: %s,真实值:%s' % (predict_results2,np.argmax(predict_results2),np.argmax(y_test[0])))