pics
456764059
2 years ago
| 196 | 196 | |
| 197 | 197 | 标签数量分布统计和可视化结果如下图: |
| 198 | 198 | |
| 199 |  | |
| 199 | 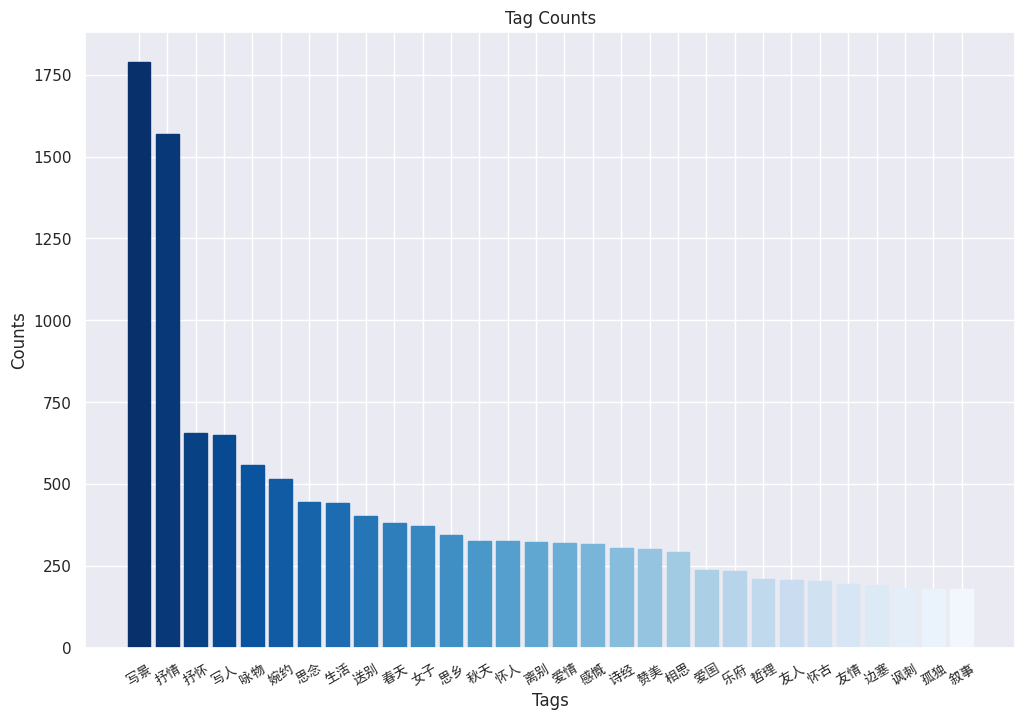 | |
| 200 | 200 | |
| 201 | 201 | 对无用标签进行清洗。去掉其中例如“唐诗三百首”、“高中必备古诗”这些无用的tag,只保留“送别”、“思乡”这类tag。 |
| 202 | 202 | |
| 286 | 286 | |
| 287 | 287 | 选择在HuggingFace上发布的`IDEA-CCNL/Wenzhong-GPT2-110M`模型,包含110M参数,使用BPE分词,在300G的悟道语料上进行预训练。该模型在封神榜系列模型中属于自然语言生成任务的通用模型。 |
| 288 | 288 | |
| 289 |  | |
| 289 | 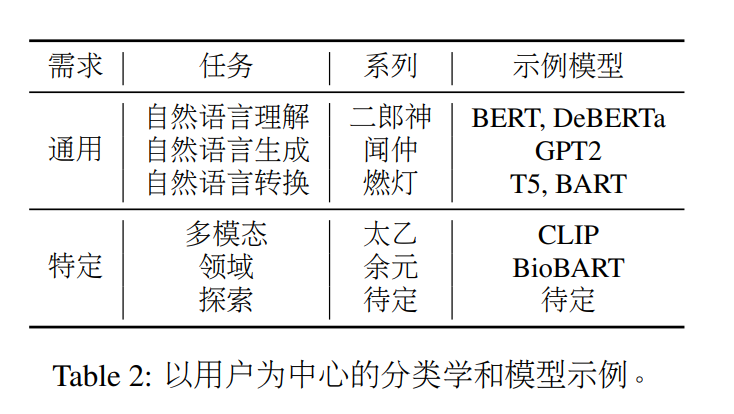 | |
| 290 | 290 | |
| 291 | 291 | 为了提升训练效率,使用peft库进行高效的微调,具体使用LoRA方法,最终仅训练1.02%的参数。 |
| 292 | 292 | |
| 442 | 442 | |
| 443 | 443 | 困惑度与测试集上的句子概率相关,其基本思想是:给测试集的句子赋予较高概率值的语言模型较好,当语言模型训练完之后,测试集中的句子都是正常的句子,那么训练好的模型就是在测试集上的概率越高越好,公式如下: |
| 444 | 444 | |
| 445 |  | |
| 445 | 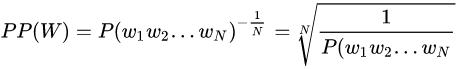 | |
| 446 | 446 | |
| 447 | 447 | 其中S表示句子,w表示词语。 |
| 448 | 448 | |
| 509 | 509 | |
| 510 | 510 | 为了使微调更有效, LoRA通过低秩分解,用两个较小的权重更新来表示权重更新矩阵。这些新矩阵可以被训练以适应新数据,同时保持较低的更改总数。原始权重矩阵保持冻结状态,不会接收任何进一步的调整。 |
| 511 | 511 | |
| 512 |  | |
| 512 | 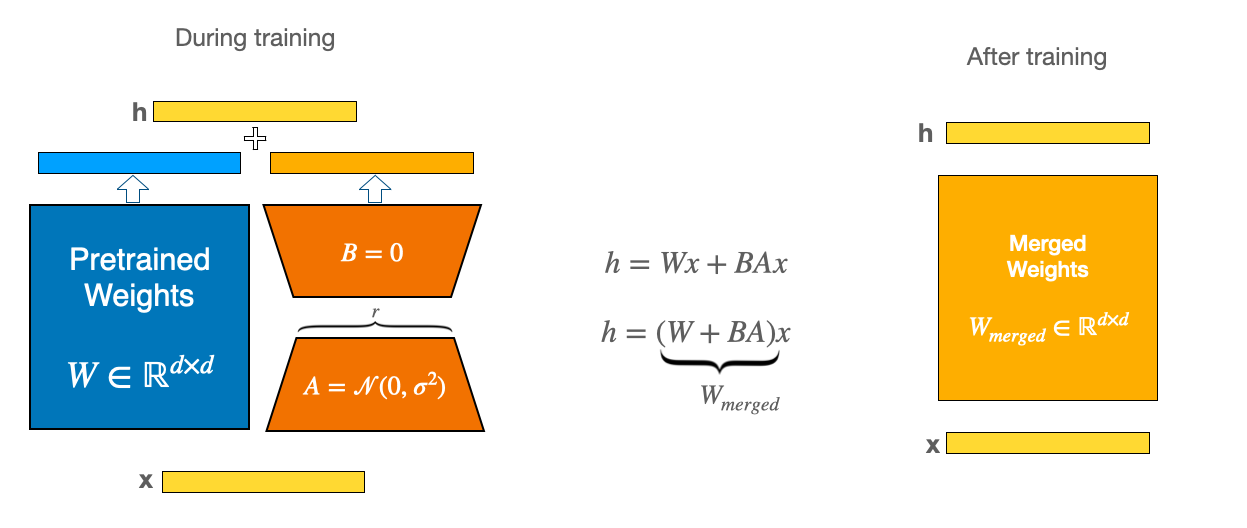 | |
| 513 | 513 | |
| 514 | 514 | ```python |
| 515 | 515 | MODEL_PATH = r"IDEA-CCNL/Wenzhong-GPT2-110M" |
| 563 | 563 | |
| 564 | 564 | 训练过程截图如下: |
| 565 | 565 | |
| 566 |  | |
| 566 |  | |
| 567 | 567 | |
| 568 | 568 | 训练过程中的loss: |
| 569 | 569 | |
| 570 |  | |
| 570 | 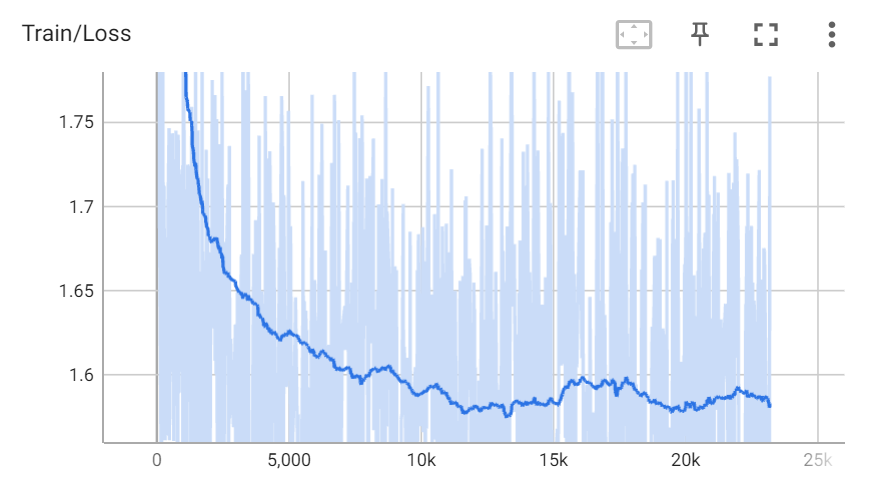 | |
| 571 | 571 | |
| 572 | 572 | ## 第二阶段模型构建与训练 |
| 573 | 573 | |
| 719 | 719 | |
| 720 | 720 | 将输入提示和模型返回结果的过程设计成gradio的交互界面,已经部署在gradio上,链接为[huggingface.co/spaces/Wendyy/poem-generate](https://huggingface.co/spaces/Wendyy/poem-generate): |
| 721 | 721 | |
| 722 |  | |
| 723 | ||
| 724 |  | |
| 722 | 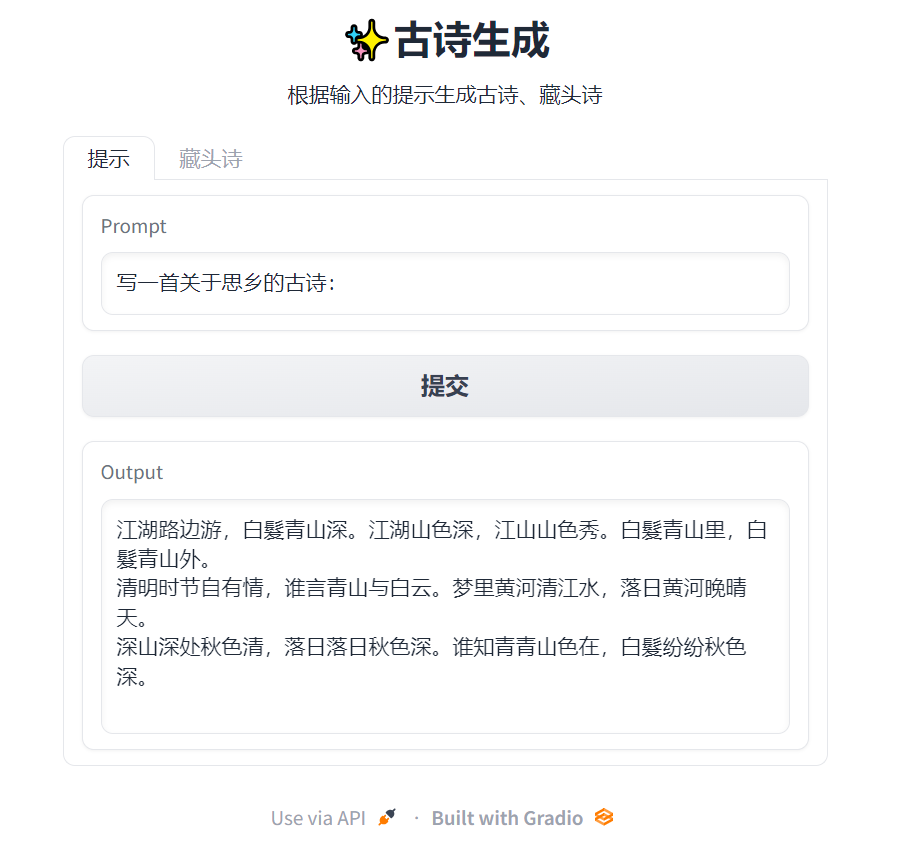 | |
| 723 | ||
| 724 | 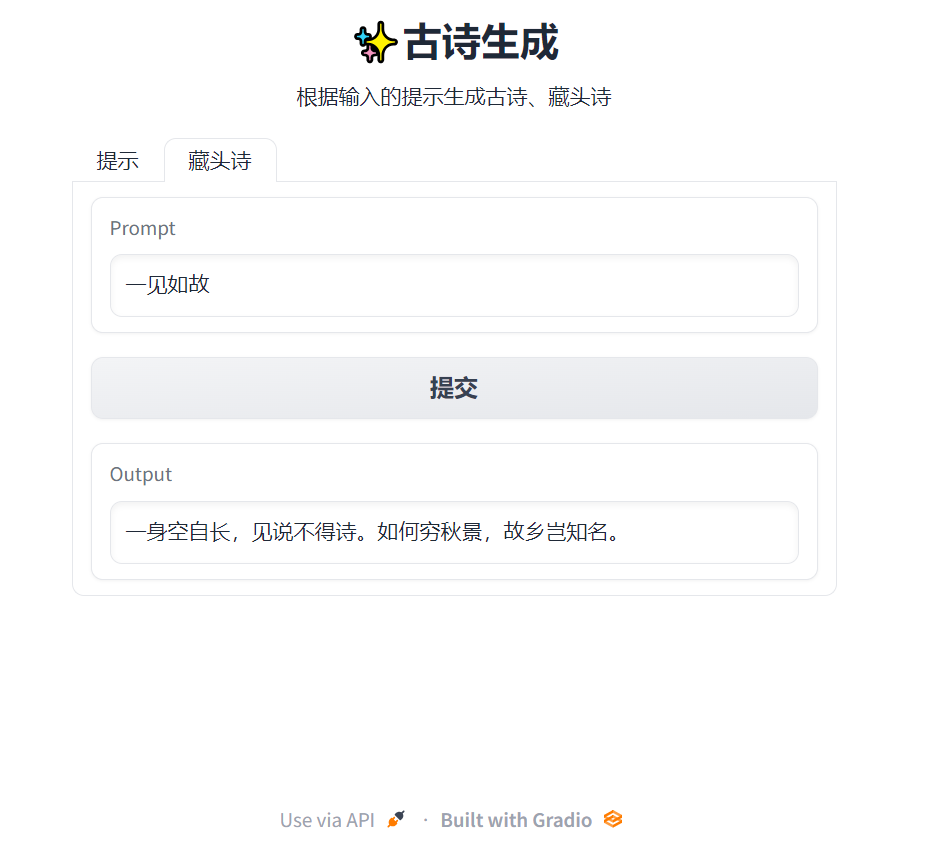 | |
| 725 | 725 | |
| 726 | 726 | ```python |
| 727 | 727 | css = """ |