diff --git a/02.03 回归分析(学生版).ipynb b/02.03 回归分析(学生版).ipynb
index 8c10f8a..47edbca 100644
--- a/02.03 回归分析(学生版).ipynb
+++ b/02.03 回归分析(学生版).ipynb
@@ -201,6 +201,109 @@
" \n",
"\n",
""
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "### 扩展内容\n",
+ "\n",
+ "**1.使用 sklearn 工具包构建回归模型**"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "我们也可以使用 sklearn 工具包来解决上面的问题。"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": 1,
+ "metadata": {},
+ "outputs": [
+ {
+ "name": "stdout",
+ "output_type": "stream",
+ "text": [
+ "[[1.53438095]]\n",
+ "[-2698.87714286]\n"
+ ]
+ }
+ ],
+ "source": [
+ "# 导入工具包\n",
+ "import numpy as np\n",
+ "from sklearn.linear_model import LinearRegression\n",
+ "\n",
+ "# 定义数据\n",
+ "x = np.array([1970, 1975, 1980, 1985, 1990, 1995, 2000, 2005]).reshape(-1,1)\n",
+ "y = np.array([325.68, 331.15, 338.69, 345.90, 354.19, 360.88, 369.48, 379.67]).reshape(-1,1)\n",
+ "\n",
+ "# 构建模型\n",
+ "reg = LinearRegression()\n",
+ "\n",
+ "# 使用数据训练模型\n",
+ "reg.fit(x, y)\n",
+ "\n",
+ "# 打印模型参数\n",
+ "print(reg.coef_)\n",
+ "print(reg.intercept_)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "**2.梯度下降法**\n",
+ "\n",
+ "在上面的例子中,不同的参数 a 和 b 将带来不同的残差值。我们把残差值更统一的称为代价函数。\n",
+ "\n",
+ "我们的目标就是选择合适的参数 a 和 b 来让这个代价函数的值最小。\n",
+ "\n",
+ "梯度下降是一个用来求函数最小值的算法,我们可以使用梯度下降算法来求出代价函数$J(\\theta_{0}, \\theta_{1})$的最小值。 \n",
+ "\n",
+ "梯度下降背后的思想是:开始时我们随机选择一个参数的组合$(\\theta_{0},\\theta_{1},......,\\theta_{n})$ ,计算代价函数,然后我们寻找下一个能让代价函数值下降最多的参数组合。我们持续这么做直到抵达一个局部最小值,因为我们并没有尝试完所有的参数组合,所以不能确定我们得到的局部最小值是否便是全局最小值,选择不同的初始参数组合,可能会找到不同的局部最小值。 \n",
+ " \n",
+ " 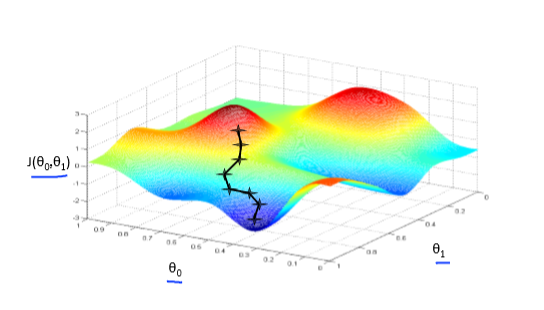 "
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "梯度下降算法的公式为:\n",
+ "\n",
+ "
"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "梯度下降算法的公式为:\n",
+ "\n",
+ " \n",
+ " \n",
+ "其中 J 是代价函数,$\\theta_{0},\\theta_{1}$ 是待求参数, α 是学习率,它决定了我们沿着能让代价函数下降程度最大的方向向下迈出的步子有多大。 "
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "对于线性回归,我们的代价函数的曲线是一个 U 型。\n",
+ "\n",
+ "
\n",
+ " \n",
+ "其中 J 是代价函数,$\\theta_{0},\\theta_{1}$ 是待求参数, α 是学习率,它决定了我们沿着能让代价函数下降程度最大的方向向下迈出的步子有多大。 "
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "对于线性回归,我们的代价函数的曲线是一个 U 型。\n",
+ "\n",
+ " \n",
+ "\n",
+ "也由于代价函数曲线是 U 形,所以梯度下降算法肯定会找到其全局最小值。"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "梯度下降其实用途广泛,不仅可以解决回归问题,也可以用来解决分类问题。在下图可以看到模型学习的过程。"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "
\n",
+ "\n",
+ "也由于代价函数曲线是 U 形,所以梯度下降算法肯定会找到其全局最小值。"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "梯度下降其实用途广泛,不仅可以解决回归问题,也可以用来解决分类问题。在下图可以看到模型学习的过程。"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ " "
]
},
{
diff --git a/02.03 回归分析.ipynb b/02.03 回归分析.ipynb
index 8de9b03..827e862 100644
--- a/02.03 回归分析.ipynb
+++ b/02.03 回归分析.ipynb
@@ -232,28 +232,101 @@
"source": [
"### 扩展内容\n",
"\n",
- "**梯度下降法**\n",
- "\n",
- "\n",
- "\n",
- "梯度下降是一个用来求函数最小值的算法。\n",
- "\n",
- "我们把上面的残差改一个名字,叫做代价函数。\n",
+ "**1.使用 sklearn 工具包构建回归模型**"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "我们也可以使用 sklearn 工具包来解决上面的问题。"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": 1,
+ "metadata": {},
+ "outputs": [
+ {
+ "name": "stdout",
+ "output_type": "stream",
+ "text": [
+ "[[1.53438095]]\n",
+ "[-2698.87714286]\n"
+ ]
+ }
+ ],
+ "source": [
+ "# 导入工具包\n",
+ "import numpy as np\n",
+ "from sklearn.linear_model import LinearRegression\n",
+ "\n",
+ "# 定义数据\n",
+ "x = np.array([1970, 1975, 1980, 1985, 1990, 1995, 2000, 2005]).reshape(-1,1)\n",
+ "y = np.array([325.68, 331.15, 338.69, 345.90, 354.19, 360.88, 369.48, 379.67]).reshape(-1,1)\n",
+ "\n",
+ "# 构建模型\n",
+ "reg = LinearRegression()\n",
+ "\n",
+ "# 使用数据训练模型\n",
+ "reg.fit(x, y)\n",
+ "\n",
+ "# 打印模型参数\n",
+ "print(reg.coef_)\n",
+ "print(reg.intercept_)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "**2.梯度下降法**\n",
+ "\n",
+ "在上面的例子中,不同的参数 a 和 b 将带来不同的残差值。我们把残差值更统一的称为代价函数。\n",
+ "\n",
+ "我们的目标就是选择合适的参数 a 和 b 来让这个代价函数的值最小。\n",
+ "\n",
+ "梯度下降是一个用来求函数最小值的算法,我们可以使用梯度下降算法来求出代价函数$J(\\theta_{0}, \\theta_{1})$的最小值。 \n",
"\n",
"梯度下降背后的思想是:开始时我们随机选择一个参数的组合$(\\theta_{0},\\theta_{1},......,\\theta_{n})$ ,计算代价函数,然后我们寻找下一个能让代价函数值下降最多的参数组合。我们持续这么做直到抵达一个局部最小值,因为我们并没有尝试完所有的参数组合,所以不能确定我们得到的局部最小值是否便是全局最小值,选择不同的初始参数组合,可能会找到不同的局部最小值。 \n",
" \n",
- " \n",
- "\n",
- "想象一下你正站立在山的这一点上,站立在你想象的公园这座红色山上,在梯度下降算法中,我们要做的就是旋转 360 度,看看我们的周围,并问自己要在某个方向上,用小碎步尽快下山。这些小碎步需要朝什么方向?如果我们站在山坡上的这一点,你看一下周围,你会发现最佳的下山方向,你再看看周围,然后再一次想想,我应该从什么方向迈着小碎步下山?然后你按照自己的判断又迈出一步,重复上面的步骤,从这个新的点,你环顾四周,并决定从什么方向将会最快下山,然后又迈进了一小步,并依此类推,直到你接近局部最低点的位置。\n"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {},
- "source": [
+ " "
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "梯度下降算法的公式为:\n",
+ "\n",
"\n",
" \n",
- "其中 α 是学习率,它决定了我们沿着能让代价函数下降程度最大的方向向下迈出的步子有多大。 "
+ "其中 J 是代价函数,$\\theta_{0},\\theta_{1}$ 是待求参数, α 是学习率,它决定了我们沿着能让代价函数下降程度最大的方向向下迈出的步子有多大。 "
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "对于线性回归,我们的代价函数的曲线是一个 U 型。\n",
+ "\n",
+ "\n",
+ "\n",
+ "也由于代价函数曲线是 U 形,所以梯度下降算法肯定会找到其全局最小值。"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "梯度下降其实用途广泛,不仅可以解决回归问题,也可以用来解决分类问题。在下图可以看到模型学习的过程。"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ ""
]
},
{
diff --git a/02.04 贝叶斯分析(学生版).ipynb b/02.04 贝叶斯分析(学生版).ipynb
index 7f6068c..8870184 100644
--- a/02.04 贝叶斯分析(学生版).ipynb
+++ b/02.04 贝叶斯分析(学生版).ipynb
@@ -105,6 +105,51 @@
"# 当邮件中出现 “红包” ,其为正常邮件的后验概率\n",
"P_normal_hongbao = P_normal * P_hongbao_normal / P_hongbao\n",
"print(\"当邮件中出现 “红包” ,其为正常邮件的后验概率为 \" + str(P_normal_hongbao))"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "### 扩展内容\n",
+ "\n",
+ "**化验结果为阳性就代表你真的患病了吗?**\n",
+ "\n",
+ "某同学 A 身体不舒服,去医院作了验血检查,看他是否得了 X 疾病,检查结果居然为阳性,他吓了一跳,赶紧上网查询。他看到网上有资料说,实验总是有误差的,这种实验有“百分之一的假阳性率和百分之一的假阴性率”。也就是说,在确实得了 X 疾病的人里面, 会有 1% 的人是假阴性,99%的人是真阳性, 也就是会有 。而没得病的人去做检查,有 1% 的人是假阳性,99% 的人是真阴性。 于是,他认为,既然误检的概率这么低,那么他确实患病的概率应该是非常高的。\n",
+ "\n",
+ "可是,医生却告诉他,他被感染的概率只有 0.09 左右。这是怎么回事呢?\n",
+ "\n",
+ "医生说:“不用害怕。99% 是测试的准确性,不是你得病的概率。你忘了考虑一件事:这种疾病的患病比例是很小的,1000个人中只有一个人有这种病。”\n",
+ "\n",
+ "医生的计算方法是这样的:因为测试的误报率是 1%,1000个人将有 10 个被报为“假阳性”,而根据 X 病在人口中的比例(1/1000=0.1%),也就是说 1000 个人里真阳性只有1个。所以,大约 11 个测试为阳性的人中才有一个是真阳性(有病)的人,因此,同学被感染的几率是大约1/11,即0.09(9%)。"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "$A$ : 普通人患 X 病\n",
+ "\n",
+ "$B$ : 化验结果为阳性\n",
+ "\n",
+ "$P(A)$ 普通人患 X 的病概率 1/1000\n",
+ "\n",
+ "$P(B)$ 化验结果为阳性的总可能性 \n",
+ "\n",
+ "$P(A|B)$:检测结果为阳性时,一个人患 X 病的概率\n",
+ "\n",
+ "$P(B|A)$:一个人患 X 病,其检测结果为阳性的概率, 99%\n",
+ "\n",
+ "根据**贝叶斯公式**:\n",
+ "\n",
+ "$$\n",
+ "\\begin{align}\n",
+ "&P(A|B)=\\frac{P(B|A){P(A)}}{P(B)}\\\\\n",
+ "=&\\frac{99\\%*(1/1000)}{99\\%*(1/1000) + 1\\%*(999/1000)}\\\\\n",
+ "=&\\frac{99}{1098}\\\\\n",
+ "≈ & 9\\%\n",
+ "\\end{align}\n",
+ "$$\n"
]
},
{
diff --git a/02.04 贝叶斯分析.ipynb b/02.04 贝叶斯分析.ipynb
index 0acba03..17569c6 100644
--- a/02.04 贝叶斯分析.ipynb
+++ b/02.04 贝叶斯分析.ipynb
@@ -105,6 +105,51 @@
"# 当邮件中出现 “红包” ,其为正常邮件的后验概率\n",
"P_normal_hongbao = P_normal * P_hongbao_normal / P_hongbao\n",
"print(\"当邮件中出现 “红包” ,其为正常邮件的后验概率为 \" + str(P_normal_hongbao))"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "### 扩展内容\n",
+ "\n",
+ "**化验结果为阳性就代表你真的患病了吗?**\n",
+ "\n",
+ "某同学 A 身体不舒服,去医院作了验血检查,看他是否得了 X 疾病,检查结果居然为阳性,他吓了一跳,赶紧上网查询。他看到网上有资料说,实验总是有误差的,这种实验有“百分之一的假阳性率和百分之一的假阴性率”。也就是说,在确实得了 X 疾病的人里面, 会有 1% 的人是假阴性,99%的人是真阳性, 也就是会有 。而没得病的人去做检查,有 1% 的人是假阳性,99% 的人是真阴性。 于是,他认为,既然误检的概率这么低,那么他确实患病的概率应该是非常高的。\n",
+ "\n",
+ "可是,医生却告诉他,他被感染的概率只有 0.09 左右。这是怎么回事呢?\n",
+ "\n",
+ "医生说:“不用害怕。99% 是测试的准确性,不是你得病的概率。你忘了考虑一件事:这种疾病的患病比例是很小的,1000个人中只有一个人有这种病。”\n",
+ "\n",
+ "医生的计算方法是这样的:因为测试的误报率是 1%,1000个人将有 10 个被报为“假阳性”,而根据 X 病在人口中的比例(1/1000=0.1%),也就是说 1000 个人里真阳性只有1个。所以,大约 11 个测试为阳性的人中才有一个是真阳性(有病)的人,因此,同学被感染的几率是大约1/11,即0.09(9%)。"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "$A$ : 普通人患 X 病\n",
+ "\n",
+ "$B$ : 化验结果为阳性\n",
+ "\n",
+ "$P(A)$ 普通人患 X 的病概率 1/1000\n",
+ "\n",
+ "$P(B)$ 化验结果为阳性的总可能性 \n",
+ "\n",
+ "$P(A|B)$:检测结果为阳性时,一个人患 X 病的概率\n",
+ "\n",
+ "$P(B|A)$:一个人患 X 病,其检测结果为阳性的概率, 99%\n",
+ "\n",
+ "根据**贝叶斯公式**:\n",
+ "\n",
+ "$$\n",
+ "\\begin{align}\n",
+ "&P(A|B)=\\frac{P(B|A){P(A)}}{P(B)}\\\\\n",
+ "=&\\frac{99\\%*(1/1000)}{99\\%*(1/1000) + 1\\%*(999/1000)}\\\\\n",
+ "=&\\frac{99}{1098}\\\\\n",
+ "≈ & 9\\%\n",
+ "\\end{align}\n",
+ "$$\n"
]
},
{
diff --git a/02.05 神经网络学习(学生版).ipynb b/02.05 神经网络学习(学生版).ipynb
index c29cf61..cc9da9e 100644
--- a/02.05 神经网络学习(学生版).ipynb
+++ b/02.05 神经网络学习(学生版).ipynb
@@ -270,12 +270,12 @@
"+ 每个隐藏层中包含若干神经元。\n",
"\n",
"神经网络流程:\n",
- "\n",
- "\n",
- "\n",
- "\n",
- "\n",
- "\n"
+ "\n",
+ "\n",
+ "\n",
+ "\n",
+ "\n",
+ "\n"
]
},
{
@@ -546,6 +546,23 @@
"source": [
"**答案 1**:(在此处填写你的答案。)"
]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "## 扩展阅读\n",
+ "1. [利用starGan算法改变人物的面部特征](https://momodel.cn/explore/5c0cc4591afd945c5177fb51?type=app)\n",
+ "2. [利用 pix2pix 将你的草图变成图片](https://momodel.cn/explore/5c0cb5df1afd945819064752?type=app)\n",
+ "3. [自动生成图片描述](https://momodel.cn/explore/5ba33f578fe30b412042ac08?&type=app&tab=1)"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": []
}
],
"metadata": {
diff --git a/02.05 神经网络学习.ipynb b/02.05 神经网络学习.ipynb
index 404a236..0af1692 100644
--- a/02.05 神经网络学习.ipynb
+++ b/02.05 神经网络学习.ipynb
@@ -272,12 +272,12 @@
"+ 每个隐藏层中包含若干神经元。\n",
"\n",
"神经网络流程:\n",
- "\n",
- "\n",
- "\n",
- "\n",
- "\n",
- "\n"
+ "\n",
+ "\n",
+ "\n",
+ "\n",
+ "\n",
+ ""
]
},
{
@@ -565,6 +565,16 @@
"print('原始模型\\n其各类别预测概率:%s,预测值: %s,真实值:%s\\n' % (predict_results,np.argmax(predict_results),np.argmax(y_test[0])))\n",
"print('只有一个隐藏层的模型\\n其各类别各类别预测概率:%s,预测值: %s,真实值:%s\\n' % (predict_results1,np.argmax(predict_results1),np.argmax(y_test[0])))\n",
"print('隐藏神经元数量更改后的模型\\n其各类别预测概率:%s,预测值: %s,真实值:%s' % (predict_results2,np.argmax(predict_results2),np.argmax(y_test[0])))"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "## 扩展阅读\n",
+ "1. [利用starGan算法改变人物的面部特征](https://momodel.cn/explore/5c0cc4591afd945c5177fb51?type=app)\n",
+ "2. [利用 pix2pix 将你的草图变成图片](https://momodel.cn/explore/5c0cb5df1afd945819064752?type=app)\n",
+ "3. [自动生成图片描述](https://momodel.cn/explore/5ba33f578fe30b412042ac08?&type=app&tab=1)"
]
},
{
diff --git a/nn_media1.mp4 b/nn_media1.mp4
new file mode 100644
index 0000000..e78b63e
Binary files /dev/null and b/nn_media1.mp4 differ
"
]
},
{
diff --git a/02.03 回归分析.ipynb b/02.03 回归分析.ipynb
index 8de9b03..827e862 100644
--- a/02.03 回归分析.ipynb
+++ b/02.03 回归分析.ipynb
@@ -232,28 +232,101 @@
"source": [
"### 扩展内容\n",
"\n",
- "**梯度下降法**\n",
- "\n",
- "\n",
- "\n",
- "梯度下降是一个用来求函数最小值的算法。\n",
- "\n",
- "我们把上面的残差改一个名字,叫做代价函数。\n",
+ "**1.使用 sklearn 工具包构建回归模型**"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "我们也可以使用 sklearn 工具包来解决上面的问题。"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": 1,
+ "metadata": {},
+ "outputs": [
+ {
+ "name": "stdout",
+ "output_type": "stream",
+ "text": [
+ "[[1.53438095]]\n",
+ "[-2698.87714286]\n"
+ ]
+ }
+ ],
+ "source": [
+ "# 导入工具包\n",
+ "import numpy as np\n",
+ "from sklearn.linear_model import LinearRegression\n",
+ "\n",
+ "# 定义数据\n",
+ "x = np.array([1970, 1975, 1980, 1985, 1990, 1995, 2000, 2005]).reshape(-1,1)\n",
+ "y = np.array([325.68, 331.15, 338.69, 345.90, 354.19, 360.88, 369.48, 379.67]).reshape(-1,1)\n",
+ "\n",
+ "# 构建模型\n",
+ "reg = LinearRegression()\n",
+ "\n",
+ "# 使用数据训练模型\n",
+ "reg.fit(x, y)\n",
+ "\n",
+ "# 打印模型参数\n",
+ "print(reg.coef_)\n",
+ "print(reg.intercept_)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "**2.梯度下降法**\n",
+ "\n",
+ "在上面的例子中,不同的参数 a 和 b 将带来不同的残差值。我们把残差值更统一的称为代价函数。\n",
+ "\n",
+ "我们的目标就是选择合适的参数 a 和 b 来让这个代价函数的值最小。\n",
+ "\n",
+ "梯度下降是一个用来求函数最小值的算法,我们可以使用梯度下降算法来求出代价函数$J(\\theta_{0}, \\theta_{1})$的最小值。 \n",
"\n",
"梯度下降背后的思想是:开始时我们随机选择一个参数的组合$(\\theta_{0},\\theta_{1},......,\\theta_{n})$ ,计算代价函数,然后我们寻找下一个能让代价函数值下降最多的参数组合。我们持续这么做直到抵达一个局部最小值,因为我们并没有尝试完所有的参数组合,所以不能确定我们得到的局部最小值是否便是全局最小值,选择不同的初始参数组合,可能会找到不同的局部最小值。 \n",
" \n",
- " \n",
- "\n",
- "想象一下你正站立在山的这一点上,站立在你想象的公园这座红色山上,在梯度下降算法中,我们要做的就是旋转 360 度,看看我们的周围,并问自己要在某个方向上,用小碎步尽快下山。这些小碎步需要朝什么方向?如果我们站在山坡上的这一点,你看一下周围,你会发现最佳的下山方向,你再看看周围,然后再一次想想,我应该从什么方向迈着小碎步下山?然后你按照自己的判断又迈出一步,重复上面的步骤,从这个新的点,你环顾四周,并决定从什么方向将会最快下山,然后又迈进了一小步,并依此类推,直到你接近局部最低点的位置。\n"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {},
- "source": [
+ " "
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "梯度下降算法的公式为:\n",
+ "\n",
"\n",
" \n",
- "其中 α 是学习率,它决定了我们沿着能让代价函数下降程度最大的方向向下迈出的步子有多大。 "
+ "其中 J 是代价函数,$\\theta_{0},\\theta_{1}$ 是待求参数, α 是学习率,它决定了我们沿着能让代价函数下降程度最大的方向向下迈出的步子有多大。 "
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "对于线性回归,我们的代价函数的曲线是一个 U 型。\n",
+ "\n",
+ "\n",
+ "\n",
+ "也由于代价函数曲线是 U 形,所以梯度下降算法肯定会找到其全局最小值。"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "梯度下降其实用途广泛,不仅可以解决回归问题,也可以用来解决分类问题。在下图可以看到模型学习的过程。"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ ""
]
},
{
diff --git a/02.04 贝叶斯分析(学生版).ipynb b/02.04 贝叶斯分析(学生版).ipynb
index 7f6068c..8870184 100644
--- a/02.04 贝叶斯分析(学生版).ipynb
+++ b/02.04 贝叶斯分析(学生版).ipynb
@@ -105,6 +105,51 @@
"# 当邮件中出现 “红包” ,其为正常邮件的后验概率\n",
"P_normal_hongbao = P_normal * P_hongbao_normal / P_hongbao\n",
"print(\"当邮件中出现 “红包” ,其为正常邮件的后验概率为 \" + str(P_normal_hongbao))"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "### 扩展内容\n",
+ "\n",
+ "**化验结果为阳性就代表你真的患病了吗?**\n",
+ "\n",
+ "某同学 A 身体不舒服,去医院作了验血检查,看他是否得了 X 疾病,检查结果居然为阳性,他吓了一跳,赶紧上网查询。他看到网上有资料说,实验总是有误差的,这种实验有“百分之一的假阳性率和百分之一的假阴性率”。也就是说,在确实得了 X 疾病的人里面, 会有 1% 的人是假阴性,99%的人是真阳性, 也就是会有 。而没得病的人去做检查,有 1% 的人是假阳性,99% 的人是真阴性。 于是,他认为,既然误检的概率这么低,那么他确实患病的概率应该是非常高的。\n",
+ "\n",
+ "可是,医生却告诉他,他被感染的概率只有 0.09 左右。这是怎么回事呢?\n",
+ "\n",
+ "医生说:“不用害怕。99% 是测试的准确性,不是你得病的概率。你忘了考虑一件事:这种疾病的患病比例是很小的,1000个人中只有一个人有这种病。”\n",
+ "\n",
+ "医生的计算方法是这样的:因为测试的误报率是 1%,1000个人将有 10 个被报为“假阳性”,而根据 X 病在人口中的比例(1/1000=0.1%),也就是说 1000 个人里真阳性只有1个。所以,大约 11 个测试为阳性的人中才有一个是真阳性(有病)的人,因此,同学被感染的几率是大约1/11,即0.09(9%)。"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "$A$ : 普通人患 X 病\n",
+ "\n",
+ "$B$ : 化验结果为阳性\n",
+ "\n",
+ "$P(A)$ 普通人患 X 的病概率 1/1000\n",
+ "\n",
+ "$P(B)$ 化验结果为阳性的总可能性 \n",
+ "\n",
+ "$P(A|B)$:检测结果为阳性时,一个人患 X 病的概率\n",
+ "\n",
+ "$P(B|A)$:一个人患 X 病,其检测结果为阳性的概率, 99%\n",
+ "\n",
+ "根据**贝叶斯公式**:\n",
+ "\n",
+ "$$\n",
+ "\\begin{align}\n",
+ "&P(A|B)=\\frac{P(B|A){P(A)}}{P(B)}\\\\\n",
+ "=&\\frac{99\\%*(1/1000)}{99\\%*(1/1000) + 1\\%*(999/1000)}\\\\\n",
+ "=&\\frac{99}{1098}\\\\\n",
+ "≈ & 9\\%\n",
+ "\\end{align}\n",
+ "$$\n"
]
},
{
diff --git a/02.04 贝叶斯分析.ipynb b/02.04 贝叶斯分析.ipynb
index 0acba03..17569c6 100644
--- a/02.04 贝叶斯分析.ipynb
+++ b/02.04 贝叶斯分析.ipynb
@@ -105,6 +105,51 @@
"# 当邮件中出现 “红包” ,其为正常邮件的后验概率\n",
"P_normal_hongbao = P_normal * P_hongbao_normal / P_hongbao\n",
"print(\"当邮件中出现 “红包” ,其为正常邮件的后验概率为 \" + str(P_normal_hongbao))"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "### 扩展内容\n",
+ "\n",
+ "**化验结果为阳性就代表你真的患病了吗?**\n",
+ "\n",
+ "某同学 A 身体不舒服,去医院作了验血检查,看他是否得了 X 疾病,检查结果居然为阳性,他吓了一跳,赶紧上网查询。他看到网上有资料说,实验总是有误差的,这种实验有“百分之一的假阳性率和百分之一的假阴性率”。也就是说,在确实得了 X 疾病的人里面, 会有 1% 的人是假阴性,99%的人是真阳性, 也就是会有 。而没得病的人去做检查,有 1% 的人是假阳性,99% 的人是真阴性。 于是,他认为,既然误检的概率这么低,那么他确实患病的概率应该是非常高的。\n",
+ "\n",
+ "可是,医生却告诉他,他被感染的概率只有 0.09 左右。这是怎么回事呢?\n",
+ "\n",
+ "医生说:“不用害怕。99% 是测试的准确性,不是你得病的概率。你忘了考虑一件事:这种疾病的患病比例是很小的,1000个人中只有一个人有这种病。”\n",
+ "\n",
+ "医生的计算方法是这样的:因为测试的误报率是 1%,1000个人将有 10 个被报为“假阳性”,而根据 X 病在人口中的比例(1/1000=0.1%),也就是说 1000 个人里真阳性只有1个。所以,大约 11 个测试为阳性的人中才有一个是真阳性(有病)的人,因此,同学被感染的几率是大约1/11,即0.09(9%)。"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "$A$ : 普通人患 X 病\n",
+ "\n",
+ "$B$ : 化验结果为阳性\n",
+ "\n",
+ "$P(A)$ 普通人患 X 的病概率 1/1000\n",
+ "\n",
+ "$P(B)$ 化验结果为阳性的总可能性 \n",
+ "\n",
+ "$P(A|B)$:检测结果为阳性时,一个人患 X 病的概率\n",
+ "\n",
+ "$P(B|A)$:一个人患 X 病,其检测结果为阳性的概率, 99%\n",
+ "\n",
+ "根据**贝叶斯公式**:\n",
+ "\n",
+ "$$\n",
+ "\\begin{align}\n",
+ "&P(A|B)=\\frac{P(B|A){P(A)}}{P(B)}\\\\\n",
+ "=&\\frac{99\\%*(1/1000)}{99\\%*(1/1000) + 1\\%*(999/1000)}\\\\\n",
+ "=&\\frac{99}{1098}\\\\\n",
+ "≈ & 9\\%\n",
+ "\\end{align}\n",
+ "$$\n"
]
},
{
diff --git a/02.05 神经网络学习(学生版).ipynb b/02.05 神经网络学习(学生版).ipynb
index c29cf61..cc9da9e 100644
--- a/02.05 神经网络学习(学生版).ipynb
+++ b/02.05 神经网络学习(学生版).ipynb
@@ -270,12 +270,12 @@
"+ 每个隐藏层中包含若干神经元。\n",
"\n",
"神经网络流程:\n",
- "\n",
- "\n",
- "\n",
- "\n",
- "\n",
- "\n"
+ "\n",
+ "\n",
+ "\n",
+ "\n",
+ "\n",
+ "\n"
]
},
{
@@ -546,6 +546,23 @@
"source": [
"**答案 1**:(在此处填写你的答案。)"
]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "## 扩展阅读\n",
+ "1. [利用starGan算法改变人物的面部特征](https://momodel.cn/explore/5c0cc4591afd945c5177fb51?type=app)\n",
+ "2. [利用 pix2pix 将你的草图变成图片](https://momodel.cn/explore/5c0cb5df1afd945819064752?type=app)\n",
+ "3. [自动生成图片描述](https://momodel.cn/explore/5ba33f578fe30b412042ac08?&type=app&tab=1)"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": []
}
],
"metadata": {
diff --git a/02.05 神经网络学习.ipynb b/02.05 神经网络学习.ipynb
index 404a236..0af1692 100644
--- a/02.05 神经网络学习.ipynb
+++ b/02.05 神经网络学习.ipynb
@@ -272,12 +272,12 @@
"+ 每个隐藏层中包含若干神经元。\n",
"\n",
"神经网络流程:\n",
- "\n",
- "\n",
- "\n",
- "\n",
- "\n",
- "\n"
+ "\n",
+ "\n",
+ "\n",
+ "\n",
+ "\n",
+ ""
]
},
{
@@ -565,6 +565,16 @@
"print('原始模型\\n其各类别预测概率:%s,预测值: %s,真实值:%s\\n' % (predict_results,np.argmax(predict_results),np.argmax(y_test[0])))\n",
"print('只有一个隐藏层的模型\\n其各类别各类别预测概率:%s,预测值: %s,真实值:%s\\n' % (predict_results1,np.argmax(predict_results1),np.argmax(y_test[0])))\n",
"print('隐藏神经元数量更改后的模型\\n其各类别预测概率:%s,预测值: %s,真实值:%s' % (predict_results2,np.argmax(predict_results2),np.argmax(y_test[0])))"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "## 扩展阅读\n",
+ "1. [利用starGan算法改变人物的面部特征](https://momodel.cn/explore/5c0cc4591afd945c5177fb51?type=app)\n",
+ "2. [利用 pix2pix 将你的草图变成图片](https://momodel.cn/explore/5c0cb5df1afd945819064752?type=app)\n",
+ "3. [自动生成图片描述](https://momodel.cn/explore/5ba33f578fe30b412042ac08?&type=app&tab=1)"
]
},
{
diff --git a/nn_media1.mp4 b/nn_media1.mp4
new file mode 100644
index 0000000..e78b63e
Binary files /dev/null and b/nn_media1.mp4 differ