# 基于大语言模型和高效微调的古诗生成模型
测试网址:[huggingface.co/spaces/Wendyy/poem-generate](https://huggingface.co/spaces/Wendyy/poem-generate)
目前该平台上的部署测试还未成功。
## 运行环境说明
- Python:`3.10.12`(安装miniconda管理Python环境)
- Pytorch:`1.13.0`
- peft: `0.4.0`
在该平台上需要创建虚拟环境以安装正确的python版本,可以使用miniconda或virtualenv,由于每次重启会删掉环境,因此将miniconda装在`/work`文件夹下,每次重启后,只需要将conda环境重新激活,方法
```shell
# 安装miniconda(只需要进行一次)
sh Miniconda3-latest-Linux-x86_64.sh
conda create -n poem python==3.10.12
pip install peft==0.4.0
pip install transformers
# 激活conda(每次重启后都需要进行)
vim ~/.bashrc
export PATH="/home/jovyan/miniconda3/bin:$PATH"
source ~/.bashrc
conda activate poem
```
virtualenv方法则更加方便,因为该平台自带virtualenv。运行下面的命令会在`/work`下创建一个环境,不会随着重启消失。
```shell
virtualenv -p miniconda3/envs/poem/bin/python3 poem_env
source poem_env/bin/activate
```
为了能在ipynb中使用配置好的环境,需要配置kernel。
```shell
python -m ipykernel install --user --name=poem
```
修改镜像源
```shell
pip3 config set global.index-url https://pypi.tuna.tsinghua.edu.cn/simple
```
## 项目结构说明
文件说明:
- data_clean 用于数据清洗
- poem_generate 第一阶段模型训练
- poem_generate_ft 第二阶段模型训练
- inference 模型推理
- app.py 部署到gradio的代码
- Jiayi_GPT2_v2.ipynb 与poem_generate代码一样
文件夹说明:
- data 存储清洗后的数据
- logs 记录模型训练日志
- checkpoint_lora_v4.1 保存模型
## 数据处理
训练使用的数据包含两个部分,一个是各种类型的古诗词文本数据,另一个是带有标签等信息的古诗词数据。
文本数据来自[chinese-poetry/chinese-poetry](https://github.com/chinese-poetry/chinese-poetry),包含了 5.5 万首唐诗、26 万首宋诗、2.1 万首宋词和其他古典文集,诗词均以繁体字存储,使用[zhconv](https://github.com/gumblex/zhconv)库可以将繁体字转为简体字。
标签数据来自[yxcs/poems-db](https://github.com/yxcs/poems-db),通过爬取古诗文网,得到了22万首古诗词以及注释赏析等信息,但是信息不全面且包含许多噪声,需要数据清洗。
模型训练分成两个阶段,第一阶段直接进行Language Modelling,使用较大规模的古诗词进行训练,使模型理解古诗词的基本结构,第二阶段添加诗词相关的标签作为提示进行Language Modelling,由于有标签的古诗词较少,所以经过过滤之后使用少量样本微调。
### chinese-poetry数据集数据处理
```python
from pathlib import Path
import json
from tqdm import tqdm
import re
import matplotlib.pyplot as plt
import random
files = [i for i in Path("chinese-poetry/json").glob("poet*")]
files.sort(key=lambda x: int(x.stem.split('.')[2]))
poems = []
for f in tqdm(files):
for item in json.load(open(f, encoding='utf-8')):
del item['strains']
poem = ''.join(item['paragraphs'])
poem = re.sub(r'(.*?)', '', poem) # 删除中文括号内的注释
if len(poem) > 100 or len(poem) < 12: # 12: 日坐竹马桥,夜宿牧牛轩。
continue
poems.append(poem)
plt.hist([len(i) for i in poems], bins=30)
plt.show()
# output
with open("tang_song_poems.txt", "w+", encoding='utf-8') as f:
f.write('\n'.join(poems))
```
由于chinese-poetry数据集的数据分散在多个json文件中,所以先将其汇总为一个txt文件,每一行是一首诗,同时先进行简单数据清洗,根据长度的分布去掉过长和过短的古诗。
```python
from tqdm import tqdm
import re
filtered = []
total_cnt = 0
with open("tang_song_poems.txt", encoding='utf-8') as f:
for line in tqdm(f.readlines()):
total_cnt += 1
line = line.strip('。')
line = line.strip('\n')
sentences = re.split(r'[,。]', line)[:-1]
lens = [len(i) for i in sentences]
if "□" in line: # 奇怪的字符
continue
if len(set(lens)) > 1: # 长度不统一
continue
if lens[0] not in (5, 7): # 非5言或7言
continue
if len(sentences) % 2 != 0: # 句数不为偶数
continue
if len(sentences) < 4 or len(sentences) > 8: # 过长
continue
#line = re.sub(r'[,。?]', ' ', line).strip()
filtered.append(line)
print(f"{len(filtered)}/{total_cnt}")
with open("tang_song_poems_filter.txt", "w+", encoding='utf-8') as f:
f.write("\n".join(filtered))
```
随后对数据进行进一步的清洗,对于一些编码错误的字符删去,同时为了降低训练难度,我们限制古诗为5言或7言,并且为2~4句。
之后根据9比1的比例分为训练集和测试集:
```python
with open("tang_song_poems_filter.txt", encoding='utf-8') as src:
lines = src.readlines()
idx = int(0.9 * len(lines))
with open("train_poems.txt", "w+", encoding='utf-8') as f:
f.write("".join(lines[:idx]))
with open("test_poems.txt", "w+", encoding='utf-8') as f:
f.write("".join(lines[idx:])
```
### 带标签古诗数据处理
数据如下所示,包含较多的元信息,准备使用的是`content`和`tags`两个字段,
```json
{'_id': {'$oid': '5c22086497880d3b825c968f'},
'content': ['\n渡远荆门外,来从楚国游。',
'山随平野尽,江入大荒流。',
'月下飞天镜,云生结海楼。',
'仍怜故乡水,万里送行舟。\n'],
'translate': ['乘船远行,路过荆门一带,来到楚国故地。',
'青山渐渐消失,平野一望无边。长江滔滔奔涌,流入广袤荒原。',
'月映江面,犹如明天飞镜;云彩升起,变幻无穷,结成了海市蜃楼。',
'故乡之水恋恋不舍,不远万里送我行舟。'],
'translate_res': ['张国举.唐诗精华注译评.长春:长春出版社,2010:128-129',
'裴斐.李白诗歌赏析集.成都:巴蜀书社,1988年2月:13-18',
'于海娣 等.唐诗鉴赏大全集.北京:中国华侨出版社,2010:116'],
'tags': ['唐诗三百首', '初中古诗', '长江', '送别', '思乡'],
'notes': ['渡远荆(jīng)门外,来从楚国游。荆门:山名,位于今湖北省宜都县西北长江南岸,与北岸虎牙三对峙,地势险要,自古即有楚蜀咽喉之称。远:远自。楚国:楚地,指湖北一带,春秋时期属楚国。',
'山随平野尽,江入大荒流。平野:平坦广阔的原野。江:长江。大荒:广阔无际的田野。',
'月下飞天镜,云生结海楼。月下飞天镜:明月映入江水,如同飞下的天镜。下:移下。海楼:海市蜃楼,这里形容江上云霞的美丽景象。',
'仍怜故乡水,万里送行舟。 仍:依然。怜:怜爱。一本作“连”。故乡水:指从四川流来的长江水。因诗人从小生活在四川,把四川称作故乡。万里:喻行程之远。'],
'reference': [],
'appreciation': ['\u3000\u3000这首诗是李白出蜀时所作。李白这次出蜀,由水路乘船远行,经巴渝,出三峡,直向荆门山之外驶去,目的是到湖北、湖南一带楚国故地游览。“渡远荆门外,来从楚国游”,指的就是这一壮游。这时候的青年诗人,兴致勃勃,坐在船上沿途纵情观赏巫山两岸高耸云霄的峻岭,一路看来,眼前景色逐渐变化,船过荆门一带,已是平原旷野,视域顿然开阔,别是一番景色:',
'\u3000\u3000“山随平野尽,江入大荒流。”',
'\u3000\u3000“山随平野尽”,形象地描绘了船出三峡、渡过荆门山后长江两岸的特有景色:山逐渐消失了,眼前是一望无际的低平的原野。著一“随”字,化静为动,将群山与平野的位置逐渐变换、推移,真切地表现出来。这句好比用电影镜头摄下的一组活动画面,给人以流动感与空间感,将静止的山岭摹状出活动的趋向来。',
'\u3000\u3000“江入大荒流”,写出江水奔腾直泻的气势,从荆门往远处望去,仿佛流入荒漠辽远的原野,显得天空寥廓,境界高远。后句著一“入”字,写出了气势的博大,充分表达了诗人的万丈豪情,充满了喜悦和昂扬的激情,力透纸背,用语贴切。景中蕴藏着诗人喜悦开朗的心情和青春的蓬勃朝气。',
'\u3000\u3000颔联这两句不仅由于写进“平野”、“大荒”这些辽阔原野的意象,而气势开阔;而且还由于动态的描写而十分生动。大江固然是流动的,而山脉却本来是凝固的,“随、尽”的动态感觉,完全是得自舟行的实际体验。在陡峭奇险,山峦叠嶂的三峡地带穿行多日后,突见壮阔之景,豁然开朗的心情可想而知。它用高度凝炼的语言。极其概括地写出了诗人整个行程的地理变化。',
'\u3000\u3000写完山势与流水,诗人又以移步换景手法,从不同角度描绘长江的近景与远景:',
'\u3000\u3000“月下飞天镜,云生结海楼。”',
'\u3000\u3000长江流过荆门以下,河道迂曲,流速减缓。晚上,江面平静时,俯视月亮在水中的倒影,好象天上飞来一面明镜似的;日间,仰望天空,云彩兴起,变幻无穷,结成了海市蜃楼般的奇景。这正是从荆门一带广阔平原的高空中和平静的江面上所观赏到的奇妙美景。如在崇山峻岭的三峡中,自非亭午夜分,不见曦月,夏水襄陵,江面水流湍急汹涌,那就很难有机会看到“月下飞天镜”的水中影像;在隐天蔽日的三峡空间,也无从望见“云生结海楼”的奇景。这一联以水中月明如圆镜反衬江水的平静,以天上云彩构成海市蜃楼衬托江岸的辽阔,天空的高远,艺术效果十分强烈。颔颈两联,把生活在蜀中的人,初次出峡,见到广大平原时的新鲜感受极其真切地写了出来。',
'\u3000\u3000颈联两句反衬江水平静,展现江岸辽阔,天空高远,充满了浪漫主义色彩。',
'\u3000\u3000李白在欣赏荆门一带风光的时候,面对那流经故乡的滔滔江水,不禁起了思乡之情:',
'\u3000\u3000“仍怜故乡水,万里送行舟。”',
'\u3000\u3000诗人顺着长江远渡荆门,江水流过的蜀地也就是曾经养育过他的故乡,初次离别,他怎能不无限留恋,依依难舍呢?但诗人不说自己思念故乡,而说故乡之水恋恋不舍地一路送我远行,怀着深情厚意,万里送行舟,从对面写来,越发显出自己思乡深情。诗以浓重的怀念惜别之情结尾,言有尽而情无穷。诗题中的“送别”应是告别故乡而不是送别朋友,诗中并无送别朋友的离情别绪。清沈德潜认为“诗中无送别意,题中二字可删”(《唐诗别裁》),这并不是没有道理的。',
'\u3000\u3000这首诗首尾行结,浑然一体,意境高远,风格雄健。“山随平野尽,江入大荒流”,写得逼真如画,有如一幅长江出峡渡荆门长轴山水图,成为脍炙人口的佳句。如果说优秀的山水画“咫尺应须论万里”,那么,这首形象壮美瑰玮的五律也可以说能以小见大,以一当十,容量丰富,包涵长江中游数万里山势与水流的景色,具有高度集中的艺术概括力。'],
'appreciation_res': ['何国治 等.唐诗鉴赏辞典.上海:上海辞书出版社,1983:302-303'],
'onlyId': '50b4388a212b8f42992a63458edbf3f7',
'name': '渡荆门送别',
'dynasty': '唐代',
'author': '李白',
'sourceLink': 'https://so.gushiwen.org/shiwenv_d50eb19399e6.aspx',
'type': '唐诗三百首',
'format': '五言律诗',
'updateAt': '2018-12-13T08:36:12.589Z'}
```
标签数量分布统计和可视化结果如下图:
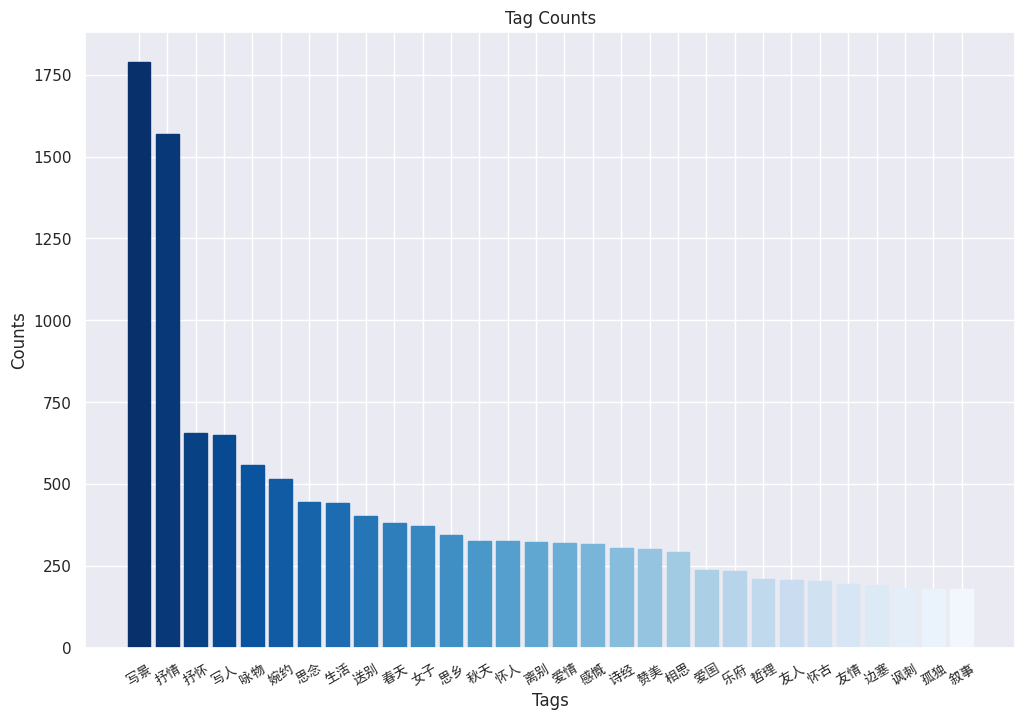
对无用标签进行清洗。去掉其中例如“唐诗三百首”、“高中必备古诗”这些无用的tag,只保留“送别”、“思乡”这类tag。
```python
from collections import Counter
import re
cnt = Counter()
for i in tag_data:
cnt.update(i['tags'])
ban_tags = []
for tag in cnt.keys():
if re.search(r'\d', tag):
ban_tags.append(tag)
elif '唐' in tag or '宋' in tag:
ban_tags.append(tag)
elif len(tag) >= 5:
ban_tags.append(tag)
elif '小学' in tag or '中学' in tag or '高中' in tag or '初中' in tag:
ban_tags.append(tag)
elif '诗经' in tag:
ban_tags.append(tag)
```
删除的标签如下:
```text
['唐诗三百首',
'早教古诗100首',
'小学生必背古诗70首',
'小学生必背古诗80首',
'初中古诗',
'小学古诗',
'古诗里的十二个月',
'高中古诗',
'写狗古诗18首',
'初中文言文',
'诗经',
'高中文言文',
'古诗十九首',
'宋词精选',
'小学文言文',
'古诗三百首',
'宋词三百首',
'春天|写人',
'离别|抒情|伤感|怀人']
```
对于内容,删去非常长的古诗,并删去其中的特殊字符、注释、英文标点符号。
```python
tag_poems = []
for item in tag_data:
# 太长的删去
if len(item['content']) > 6:
continue
if '诗经' in item['tags']:
continue
# 无意义tag删去
refined_tags = [i for i in item['tags'] if i not in ban_tags]
if len(refined_tags) == 0:
continue
refined_content = ''.join(item['content'])
refined_content = re.sub(r'[A-Za-z0-9\s/<>《》〔〕]', '', refined_content)
refined_content = re.sub(r'(.*?)', '', refined_content)
refined_content = re.sub(r'\(.*?\)', '', refined_content)
# refined_content = re.sub(r'[,。?,]', ' ', refined_content)
refined_content.replace(',', ',').replace('?', '?').replace('!', '!')
refined_content = refined_content.strip()
# 词删去(字数不一)
if len(set([len(i) for i in re.split(r'[,。?!]', refined_content)[:-1]])) > 1:
continue
# 太长的删去
if len(refined_content) > 150:
continue
tag_poems.append({
'tags': ' '.join(refined_tags),
'content': refined_content
})
```
## 第一阶段模型构建与训练
由于目前已有许多预训练语言模型,所以选择了使用大语料训练过的模型进行微调。
选择在HuggingFace上发布的`IDEA-CCNL/Wenzhong-GPT2-110M`模型,包含110M参数,使用BPE分词,在300G的悟道语料上进行预训练。该模型在封神榜系列模型中属于自然语言生成任务的通用模型。
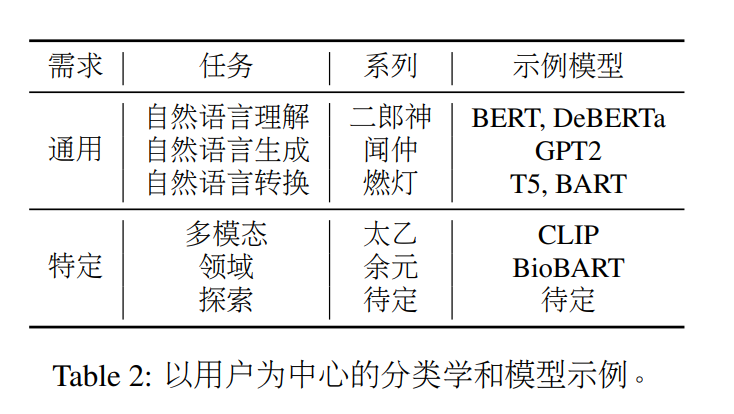
为了提升训练效率,使用peft库进行高效的微调,具体使用LoRA方法,最终仅训练1.02%的参数。
### 导入相关库
```python
import time
import math
import random
import numpy as np
import torch
import torch.nn as nn
from tqdm import tqdm
import transformers
from tensorboardX import SummaryWriter # 这个库提供Tensorboard的日志功能
from transformers import AutoTokenizer, AutoModelForCausalLM
from torch.utils.data import Dataset, DataLoader
from peft import TaskType, LoraConfig, get_peft_model
```
### 构建数据集和处理输入数据
PoemDataset用于构建诗歌数据集。
```python
class PoemDataset(Dataset):
def __init__(self, path):
super().__init__()
self.poems = open(path, encoding='utf-8').readlines() # [:30000]
def __getitem__(self, idx):
text = self.poems[idx].strip()
return text
def __len__(self):
return len(self.poems)
```
prepare_inputs用于处理输入的样本。首先使用随机选择的prompt作为输入的前缀,并使用tokenizer将其转换为模型可接受的输入格式。然后,将样本列表samples使用tokenizer转换为模型可接受的输入格式。最后,将prompt的输入和样本的输入拼接在一起,生成input_ids、label_ids和注意力掩码。需要注意prompt在训练过程不参与loss的计算,因此对其进行`*-100`的操作。
使用Hugging Face的transformers库中的AutoTokenizer类从预训练模型路径(MODEL_PATH)加载tokenizer。并且将填充标记设置为eos(end of sentence)标记,这样会使模型处理填充部分的表示更加连贯,效果会更好。
```python
tokenizer = AutoTokenizer.from_pretrained(MODEL_PATH)
tokenizer.pad_token = tokenizer.eos_token
prompts = [
"写一首唐诗:",
"写一首古诗:",
"写一首绝句:",
"生成一首唐诗:",
"生成一首古诗:",
"生成一首绝句:",
"这是一首唐诗:",
"这是一首古诗:",
"这是一首古代诗歌:",
"生成一首压韵的古诗:",
]
def prepare_inputs(samples):
prompt_inputs = tokenizer([random.choice(prompts)] * len(samples),
padding="longest", truncation=True, add_special_tokens=False, return_tensors='pt')
inputs = tokenizer(samples, padding="longest", truncation=True, add_special_tokens=False, return_tensors='pt')
input_ids = torch.cat([
prompt_inputs.input_ids,
inputs.input_ids
], dim=1)
label_ids = torch.cat([
torch.ones_like(prompt_inputs.input_ids) * -100, # no loss for prompt
inputs.input_ids
], dim=1)
attention_mask = torch.cat([prompt_inputs.attention_mask, inputs.attention_mask], dim=1)
return input_ids, attention_mask, label_ids
```
调用诗歌数据集,构建训练验证数据集。
```python
# prepare data
train_dataset = PoemDataset("train_poems_v2.txt")
test_dataset = PoemDataset("test_poems_v2.txt")
train_dataloader = DataLoader(train_dataset, batch_size=batch_size, shuffle=True)
val_dataloader = DataLoader(test_dataset, batch_size=batch_size, shuffle=False)
```
### 定义训练模型函数
定义用于训练模型的train函数。使用tensorboard在训练过程中记录训练日志。
```python
def train(model: nn.Module, dataloaders, optimizer, scheduler, **kwargs):
"""训练的主函数"""
train_loader, test_loader = dataloaders
device = kwargs['device']
writer = SummaryWriter(kwargs['logger_name'])
model = model.to(device)
for epoch in range(kwargs['max_epochs']):
# ========== Train ==========
loss_list = []
model.train()
last_time = time.time()
for local_step, inputs in enumerate(train_loader):
step = epoch * kwargs['steps_per_epoch'] + local_step
input_ids, attention_mask, label_ids = prepare_inputs(inputs)
optimizer.zero_grad()
with torch.autocast(device_type='cuda'): # fp16
outputs = model(
input_ids=input_ids.to(device),
attention_mask=attention_mask.to(device),
labels=label_ids.to(device),
return_dict=True,
)
loss = outputs.loss
loss.backward()
optimizer.step()
scheduler.step()
# log
loss_list.append(loss.detach().cpu().item())
if (local_step % 50 == 0 and local_step != 0) or local_step == kwargs['steps_per_epoch'] - 1:
avg_loss = sum(loss_list) / len(loss_list)
n_step_time = time.time() - last_time
left_time = (kwargs['steps_per_epoch'] - local_step) // 50 * n_step_time
print("Epoch {}/{} | Step {}/{} | loss:{:.5f} time:{:.1f}s left:{:.1f}m".format(
epoch, kwargs['max_epochs'], local_step, kwargs['steps_per_epoch'],
avg_loss, n_step_time, left_time / 60
))
last_time = time.time()
writer.add_scalar('Train/Loss', loss, step)
writer.add_scalar('Epoch', epoch, step)
# if local_step %
# torch.save(model.named_parameters(), "checkpoint.pth")
model.save_pretrained("checkpoint_lora_v4")
# ========== Eval ==========
evaluate(model, test_loader, epoch, **kwargs)
print("=" * 53)
# ========== Inference ==========
inference(model)
```
### 定义验证模型函数
定义用于验证的evaluate函数,并计算loss和perplexity(PPL)。erplexity的中文是困惑度,困惑度一般来说是用来评价语言模型好坏的指标。
困惑度与测试集上的句子概率相关,其基本思想是:给测试集的句子赋予较高概率值的语言模型较好,当语言模型训练完之后,测试集中的句子都是正常的句子,那么训练好的模型就是在测试集上的概率越高越好,公式如下:
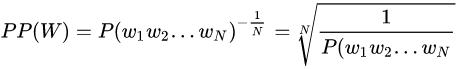
其中S表示句子,w表示词语。
```python
@torch.no_grad()
def evaluate(model, test_loader, epoch, **kwargs):
loss_list = []
ppl_list = []
print("-" * 20 + " Evaluating " + "-" * 20)
model.eval()
with torch.no_grad():
for local_step, inputs in enumerate(tqdm(test_loader)):
input_ids, attention_mask, label_ids = prepare_inputs(inputs)
outputs = model(
input_ids=input_ids.to(device),
attention_mask=attention_mask.to(device),
labels=label_ids.to(device),
return_dict=True,
)
loss_list.append(outputs.loss.cpu().item())
# PPL
probs = torch.softmax(outputs.logits, dim=-1).max(dim=-1)[0] # BLC->BL
ppl = torch.exp(-probs.log().mean(-1))
ppl_list.append(ppl.mean().cpu().item())
# log
avg_loss = sum(loss_list) / len(loss_list)
avg_ppl = sum(ppl_list) / len(ppl_list)
print(f"Epoch {epoch}/{kwargs['max_epochs']} | loss:{avg_loss:.5f} | ppl: {avg_ppl: 5f}")
# writer.add_scalar('Test/Loss', sum(loss_list) / len(loss_list), epoch * kwargs['steps_per_epoch'])
```
### 定义模型推理函数
输入提示,并将其进行tokenizer,即可生成古诗。模型可以设置最大输出长度,top-p等
top-p是一种用于在文本生成中控制输出的策略,控制生成结果的多样性。top-p算法保留累计概率之和达到一个给定阈值p的概率分布中的词汇,然后在这个分布中进行随机采样,从而生成一个单词。
```python
@torch.no_grad()
def inference(model):
inputs = tokenizer("写一首唐诗:折戟沉沙铁未销,自将磨洗认前朝。", add_special_tokens=False, return_tensors='pt')
inputs = inputs.to(device)
outputs = model.generate(
**inputs,
return_dict_in_generate=True,
max_length=150,
do_sample=True,
top_p=0.6,
num_return_sequences=5
)
for line in tokenizer.batch_decode(outputs.sequences, skip_special_tokens=True):
print(line)
```
### 构建模型
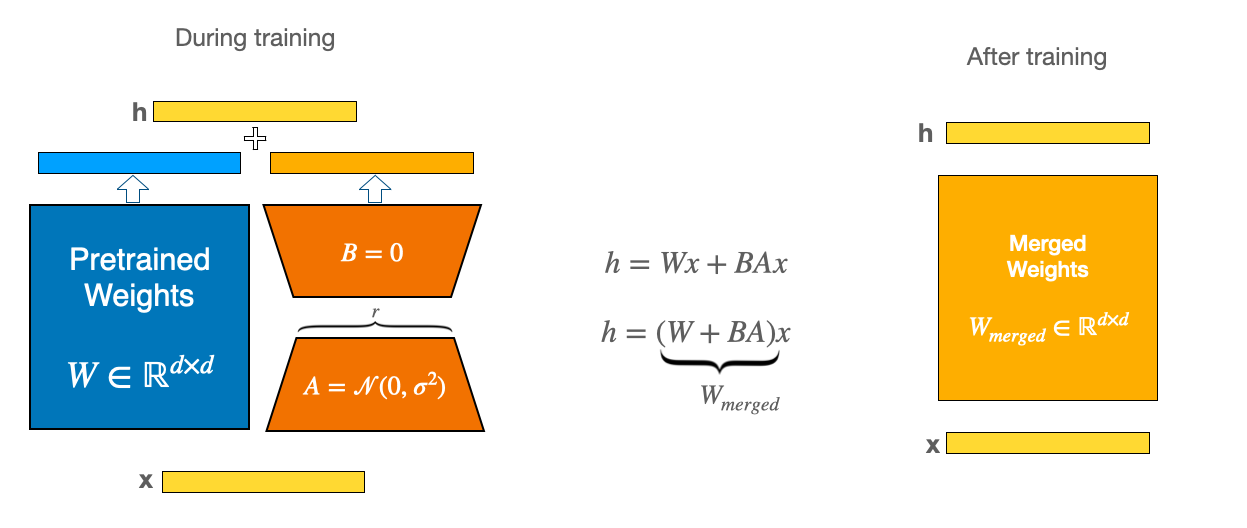
准备预训练模型并进行模型微调。gpt2_model是从预训练模型中加载的,peft_config指定了任务类型、推理模式、r、lora_alpha、lora_dropout和偏置。
- r (int): Lora矩阵的最小维度
- lora_dropout (float): Lora层的dropout概率
- lora_alpha (float): LoRA 缩放因子
- bias:指定是否应训练参数。
为了使微调更有效, LoRA通过低秩分解,用两个较小的权重更新来表示权重更新矩阵。这些新矩阵可以被训练以适应新数据,同时保持较低的更改总数。原始权重矩阵保持冻结状态,不会接收任何进一步的调整。
```python
MODEL_PATH = r"IDEA-CCNL/Wenzhong-GPT2-110M"
# prepare model
gpt2_model = AutoModelForCausalLM.from_pretrained(MODEL_PATH)
peft_config = LoraConfig(
task_type=TaskType.CAUSAL_LM,
inference_mode=False,
r=32, lora_alpha=16, lora_dropout=0.1, bias='all'
)
gpt2_model = get_peft_model(gpt2_model, peft_config)
gpt2_model.print_trainable_parameters()
```
### 训练模型
设置超参数、优化器
```python
# Hyperparameter
batch_size = 32
lr = 1e-4
device = torch.device('cuda')
max_epochs = 4
num_warmup_steps = 200
num_training_steps = max_epochs * math.ceil(len(train_dataset) / batch_size)
seed = 2023
logger_name = "Jiayi_GPT2_202307091512"
# prepare optimizer
optim = torch.optim.AdamW(filter(lambda p: p.requires_grad, gpt2_model.parameters()), lr=lr)
sche = transformers.get_linear_schedule_with_warmup(optim, num_warmup_steps, num_training_steps)
```
训练模型
```python
# train
train(
gpt2_model,
(train_dataloader, val_dataloader),
optimizer=optim,
scheduler=sche,
device=device,
max_epochs=max_epochs,
logger_name=logger_name,
steps_per_epoch=len(train_dataloader)
)
```
训练过程截图如下:

训练过程中的loss:
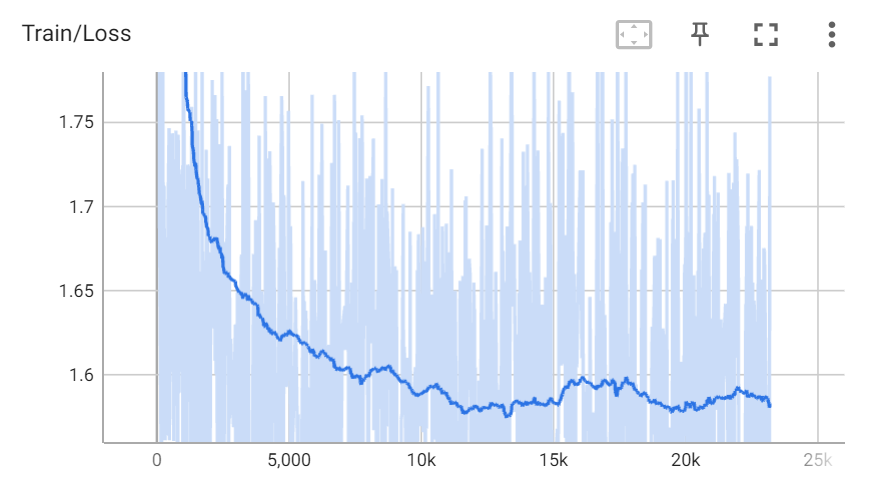
## 第二阶段模型构建与训练
第一阶段训练的模型没有诗词标签,无法指定特定类型的诗歌。因此,利用带标签数据集进行第二阶段训练。
### 构建数据集和处理输入数据
与第一阶段不同的是数据需要构造关于tag的提示。
```python
class TagPoemDataset(Dataset):
def __init__(self, path):
super().__init__()
self.poems = open(path, encoding='utf-8').readlines()
def __getitem__(self, idx):
tag, poem = self.poems[idx].strip().split('|')
tag = "写一首关于" + tag.replace(' ', '、') + "的古诗:"
return tag, poem
def __len__(self):
return len(self.poems)
```
处理输入数据,同时处理tag和诗歌。
```python
def prepare_inputs(samples):
tags, poems = samples
bs = len(tags)
prompt_inputs = tokenizer(tags, add_special_tokens=False)
poems_inputs = tokenizer(poems, add_special_tokens=False)
prompt_len = [len(i) for i in prompt_inputs.input_ids]
input_ids_list = [x1 + x2 for x1, x2 in zip(prompt_inputs.input_ids, poems_inputs.input_ids)]
max_len = max([len(i) for i in input_ids_list])
input_ids = torch.ones(bs, max_len, dtype=torch.long) * tokenizer.pad_token_id
attention_mask = torch.zeros(bs, max_len, dtype=torch.long)
for i in range(bs):
input_ids[i, :len(input_ids_list[i])] = torch.tensor(input_ids_list[i])
attention_mask[i, :len(input_ids_list[i])] = 1
label_ids = input_ids.clone()
for i in range(bs):
label_ids[i, :prompt_len[i]] = -100
return input_ids, attention_mask, label_ids
```
模型训练和模型推理的过程和第一阶段很类似,在此不再赘述。
### 构建模型
这里选择了更大的WenZhong模型,其他过程与第一阶段类似。
```python
MODEL_PATH = r"IDEA-CCNL/Wenzhong2.0-GPT2-3.5B-chinese"
```
### 训练模型
设置超参数:这里的训练数据少,因此batchsize更小。由于属于第二阶段训练,学习率也提高了。
```python
# Hyperparameter
batch_size = 4
lr = 5e-4
device = torch.device('cuda')
max_epochs = 10
num_warmup_steps = 50
num_training_steps = max_epochs * math.ceil(len(train_dataset) / batch_size)
seed = 2023
```
## 根据提示生成藏头诗
通过限制第一个字的输入生成藏头诗,并且设置停止符号为中文标点`,。`,从而控制一句诗的结束。
```python
class ChineseCharacterStop(StoppingCriteria):
def __init__(self, chars: list[str]):
self.chars = [
tokenizer(i, add_special_tokens=False, return_tensors='pt').input_ids
for i in chars
]
# for chars, tokens in zip(chars, self.chars):
# print(f"'{chars}':{tokens}")
def __call__(self, input_ids: torch.LongTensor,
scores: torch.FloatTensor, **kwargs) -> bool:
for c in self.chars:
c = c.to(input_ids.device)
match = torch.eq(input_ids[..., -c.shape[1]:], c)
if torch.any(torch.all(match, dim=1)):
return True
return False
tokenizer = AutoTokenizer.from_pretrained("IDEA-CCNL/Wenzhong-GPT2-110M")
tokenizer.pad_token = tokenizer.eos_token
gpt2_model = AutoModelForCausalLM.from_pretrained("IDEA-CCNL/Wenzhong-GPT2-110M")
model = PeftModel.from_pretrained(gpt2_model, 'checkpoint_lora_v4.1')
def cang_tou(tou: str):
poem_now = "写一首唐诗:"
for c in tou:
poem_now += c
print(poem_now)
inputs = tokenizer(poem_now, return_tensors='pt')
outputs = model.generate(
**inputs,
return_dict_in_generate=True,
max_length=150,
do_sample=True,
top_p=0.4,
num_beams=1,
num_return_sequences=1,
stopping_criteria=[ChineseCharacterStop(['。', ','])],
pad_token_id=tokenizer.pad_token_id
)
poem_now = tokenizer.batch_decode(outputs.sequences, skip_special_tokens=True)[0]
print(poem_now)
return poem_now[6:]
def prompt_gen(prompt):
inputs = tokenizer(prompt, return_tensors='pt')
outputs = model.generate(
**inputs,
return_dict_in_generate=True,
max_length=200,
do_sample=True,
top_p=0.8,
num_beams=5,
num_return_sequences=3,
# stopping_criteria=[ChineseCharacterStop(['。', ',', ''])],
pad_token_id=tokenizer.pad_token_id
)
res = ''
for line in tokenizer.batch_decode(outputs.sequences, skip_special_tokens=True):
line = line[len(prompt):]
res = res+line+'\n'
return res
```
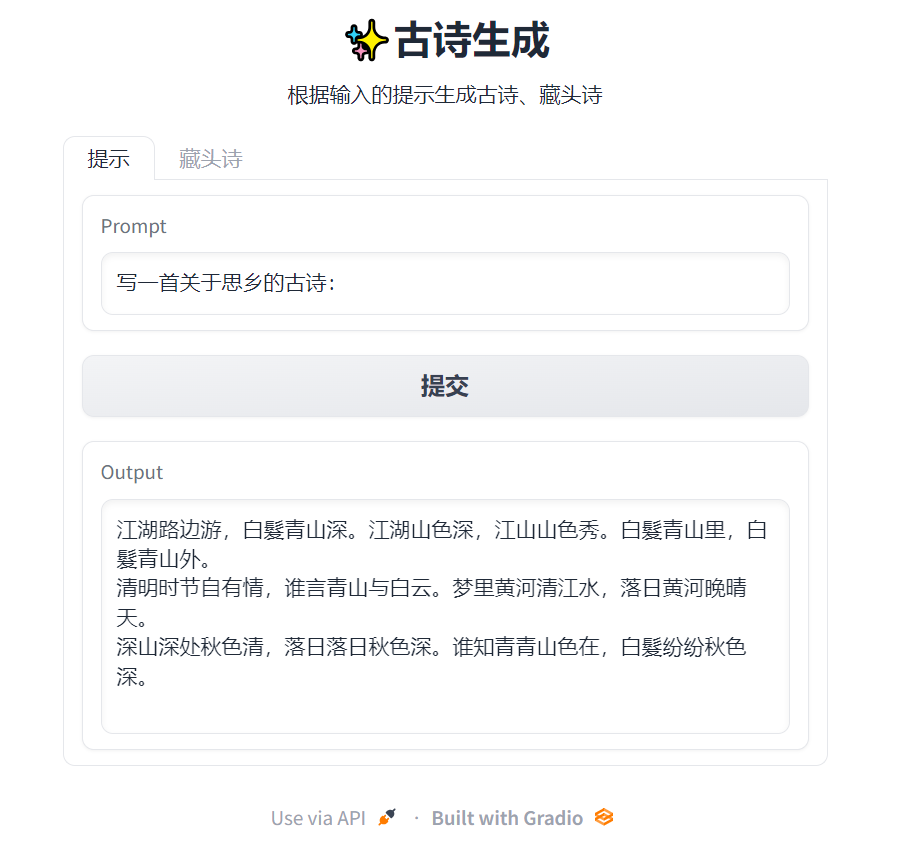
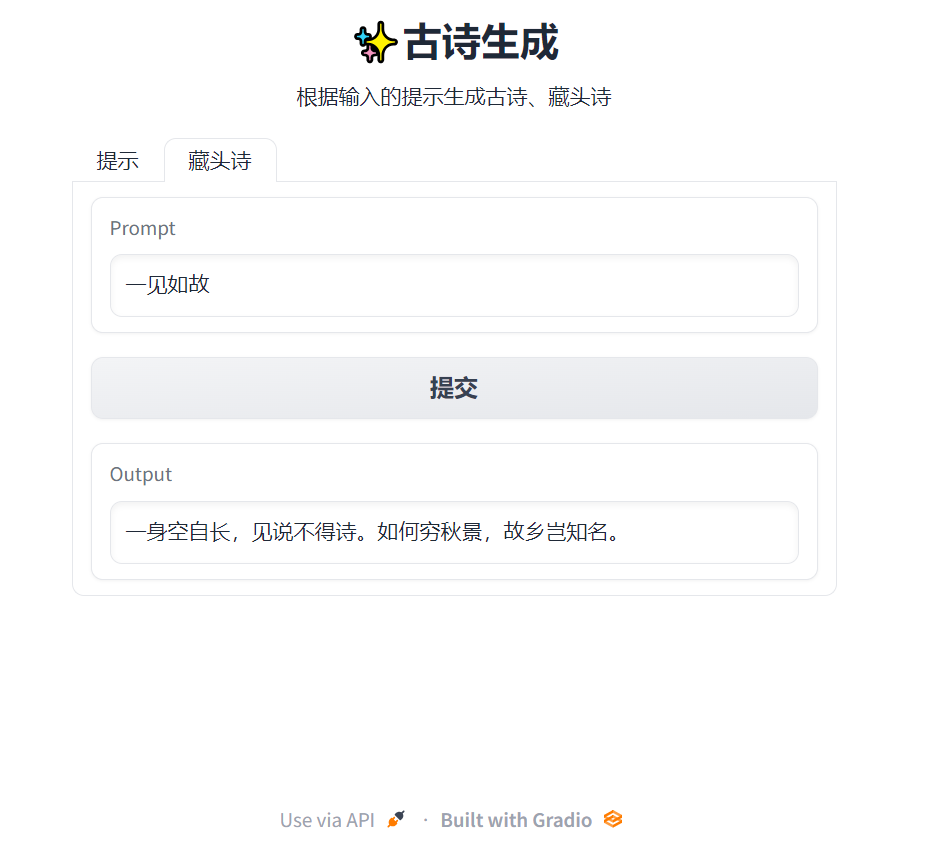
## 设计交互界面
将输入提示和模型返回结果的过程设计成gradio的交互界面,已经部署在gradio上,链接为[huggingface.co/spaces/Wendyy/poem-generate](https://huggingface.co/spaces/Wendyy/poem-generate):
```python
css = """
#col-container {max-width: 510px; margin-left: auto; margin-right: auto;}
a {text-decoration-line: underline; font-weight: 600;}
.animate-spin {
animation: spin 1s linear infinite;
}
"""
with gr.Blocks(css=css) as demo:
with gr.Column(elem_id="col-container"):
gr.Markdown(
"""
<h1 style="text-align: center;">✨古诗生成</h1>
<p style="text-align: center;">
根据输入的提示生成古诗、藏头诗<br />
</p>
"""
)
with gr.Tab("提示"):
prompt_in = gr.Textbox(label="Prompt", placeholder="写一首关于思乡的古诗:", elem_id="prompt-in")
submit_btn = gr.Button("Submit")
poetry_result = gr.Textbox(label="Output", elem_id="poetry-output")
submit_btn.click(fn=prompt_gen,
inputs=[prompt_in],
outputs=[poetry_result])
with gr.Tab("藏头诗"):
tou_in = gr.Textbox(label="Prompt", placeholder="一见如故", elem_id="tou-in")
submit_btn = gr.Button("Submit")
cangtou_result = gr.Textbox(label="Output", elem_id="cangtou-output")
submit_btn.click(fn=cang_tou,
inputs=[tou_in],
outputs=[cangtou_result])
demo.queue(max_size=12).launch()
```
## 生成结果展示
### 根据输入的提示写诗
**写一首抒情诗:**
山色秋色清,山色晚晴晴。明月满空山,暮云暗掩山。
**写一首关于思乡的古诗:**
清明时节自有情,谁言青山与白云。梦里黄河清江水,落日黄河晚晴天。
**写一首关于咏物的古诗:**
秋风细雨绵绵起,江湖路边纷纷起。江山自有青山在,白云自有白云飞。
### 藏头诗
**嘉怡:**嘉宾结觞酒,怡然笑百年。
**人工智能:**人间绝美境,工夫终不成。智慧空非善,能悟智有道。
**一二三四:**一鸟高飞倚江湖,二月春风秋江深。三百里外秋色绝,四十年来花落尽。
**奇思妙想:**奇观秋色绕江山,思念梅花满山城。妙趣更欲觅第一,想见长江源头头。
**三元牛奶:**三百里马驰骋空,元日晚来见梅花。牛羊鸣蛇觅石马,奶茶烹鹅做猪笼。
通过多次尝试,可以看出藏头诗的生成结果要比根据提示写诗的效果好。这是因为带有标签的数据集是较少的,噪声也很大。藏头诗通过开头的字总领全诗,规范整首诗的写作,更为通顺流畅和语义丰富。
## 总结和展望
该古诗生成模型兼有丰富预训练语料和高效微调的优点,可以根据输入的提示(带有古诗主题标签的提示)生成该主题的古诗,还可以根据输入的文字生成藏头诗。虽然尚未进行定量的生成效果评估,但从主观评价的角度,生成结果具有语句流畅、语义丰富、贴合主题等优点。
未来可以对这个模型进行指标评价,并通过设置更多规则(如抑扬顿挫、押韵等)来提升生成结果。此外,模型生成结果的意蕴还有待提升,缺乏真正的思想和情感,通过更多的语料、提示、标注信息将有可能对此进行提升。